夕枫 | 笔绘人生
夕枫 | 笔绘人生在之前的文章中已经详细介绍了筛选上下文,相信大家对筛选上下文已经有了深刻的理解。那么在这个基础上学习行上下文转换将会非常简单,只需要将行上下文转换的规则搞明白,立刻就可以使用筛选上下文的相关知识,从而把行上下文与筛选上下文串联起来,彻底掌握DAX的计值上下文。
什么是行上下文转换
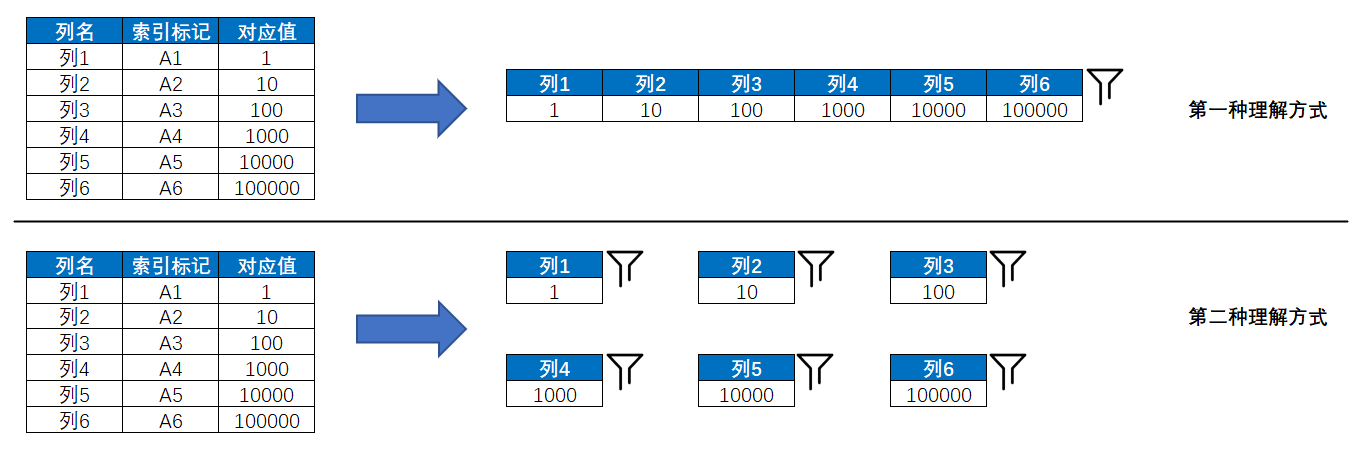
行上下文转换是指为某个行上下文里包含的所有列设置筛选器,筛选的内容为各个列在此行上下文里的索引标记所对应的值,在设置完筛选器后将丢弃此行上下文。此外,由于各列在某个行上下文里所包含的索引标记都只有一个,因此在转化成的筛选器中,每个列都只筛选一个值,所以可以将行上下文转换后所设置的筛选器理解成一个筛选多列的固化筛选器,也可以理解成多个标准筛选器,这两种理解方式都是没问题的,最终都会殊途同归。
总之,行上下文转换就是把行上下文转换成一组筛选器,这些筛选器再进行交互,然后产生筛选上下文,因此行上下文转换的产物就是筛选上下文,所以在别的资料上可能会这样描述:“行上下文会转换成筛选上下文”,这样描述其实也没错,但却没有把行上下文转换的本质说清楚,所以遇到这样的描述要能第一时间反应过来。此外,需要特别注意,行上下文转换后会丢弃原有的行上下文,即转换完成后就不存在任何行上下文了。而且行上下文转换这个过程不可逆,即不存在逆操作把筛选上下文还原成行上下文。
需要重点注意,当某个基础表被用作筛选器参数或者该基础表的行上下文被转换成筛选上下文后,其扩展表上不属于基础表自身列的其他列也会设置筛选器!
单层行上下文时的行上下文转换
1、简单应用
单层行上下文的转换非常直观,相信都能理解。那下面就通过一个简单例子来介绍下,具体如下图所示:
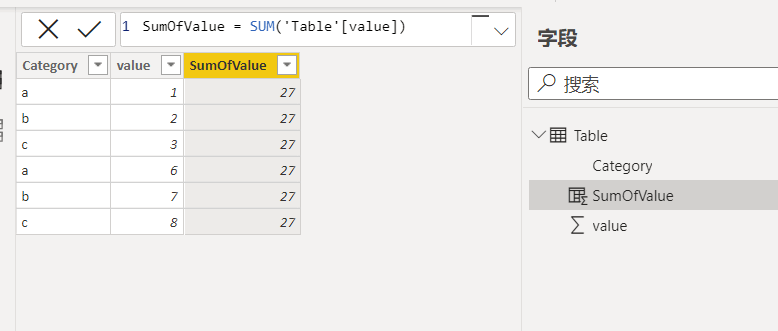
相信很多人在刚学习DAX时都遇到过上面这个情况吧,然后就疑惑:为什么整列的值都是总计值,而不是每一行所对应的单个值。那么在掌握了筛选上下文后,这个问题可以说是非常简单了。之所以整列都是总计值,那是因为在计算列的初始计值环境里不存在任何筛选器,所以筛选上下文里的数据为所有数据,故导致每一行的结果都是总计值。
那么接下来,把这个计算列的表达式用度量值重写,具体的度量值表达式如下:
SumOfValue-Measure = SUM('Table'[value])然后再在计算列里引用这个度量值,结果如下图所示:
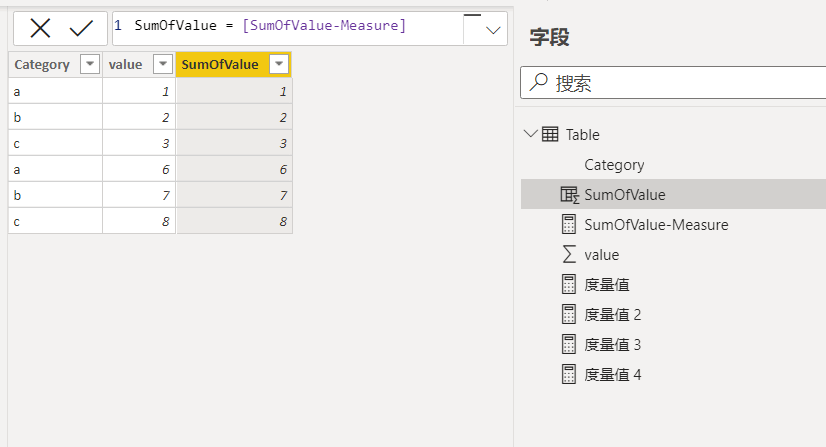
此时,所引用的度量值的表达式与之前的计算列表达式一致,但为何在计算列里引用这个度量值的结果却不一致呢。这个原因就在于:
- DAX引擎会自动为每一个度量值的引用套上一个CALCULATE函数
- 行上下文遇到CALCULATE函数时,会发生行上下文转换,变成筛选上下文
也就是说在计算列里引用度量值,会使行上下文发生转换,变成筛选上下文。简单来说就是会为每一行的各个列设置筛选器,筛选的内容即为各列在当前行的对应值。由于上面这个例子中的每一行都不重复,所以行上下文转换后所得到的筛选器筛选出来的可见数据就只有一行,即当前行的数据,故SUM函数汇总后的值与当前行的值一致。
引用度量值会使行上下文发生转换的原因是因为DAX引擎自动添加的CALCULATE函数导致的,因此完全可以不新建度量值,直接在原有计算列表达式上添加CALCULATE函数,也能达到同样效果。具体如下图所示:
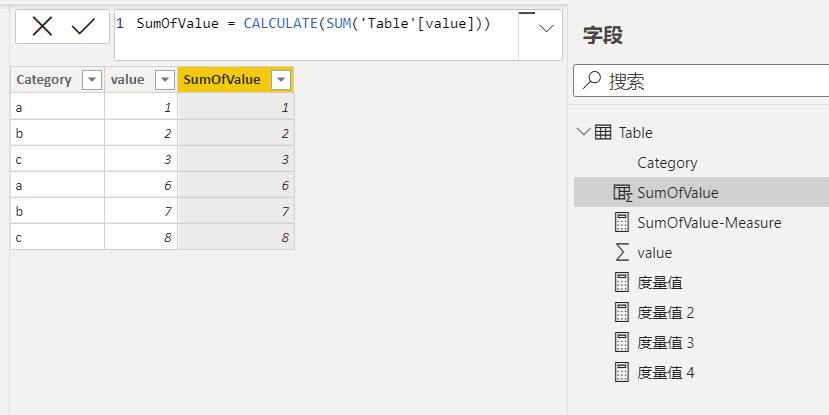
需要注意,行上下文转换后所得到的筛选上下文并不一定只有当前行这一行可见数据,当基础表里存在重复行时,那么由某个行上下文转换而来的筛选上下文的可见数据有可能是包含多行的,虽然这些行都是相同的。
下面再来看一个例子,假设现在需要添加一个计算列来计算当前类别对应的所有值中的最大值,结果如下图所示:

其中使用到的计算列表达式如下:
MaxValueOfCategory = CALCULATE(MAX('Table'[value]),ALLEXCEPT('Table','Table'[Category]))其实这个例子很简单,只需要找到当前行的类别在基础表中所对应的所有值,然后再取最大即可。当行上下文发生转换后,可以得到三个筛选器,而在这个例子中只需要类别筛选器即可,因此只要把其它筛选器移除掉就可以得到当前行的类别所对应的所有值,然后在修改后的筛选上下文里直接取最大值即可。
2、行上下文转换与扩展表
前面说到,当某个基础表被用作筛选器参数或者该基础表的行上下文被转换成筛选上下文后,其扩展表上不属于基础表自身列的其他列也会设置筛选器。那么下面就通过一个小例子来验证一下,用到的模型与数据如下图:
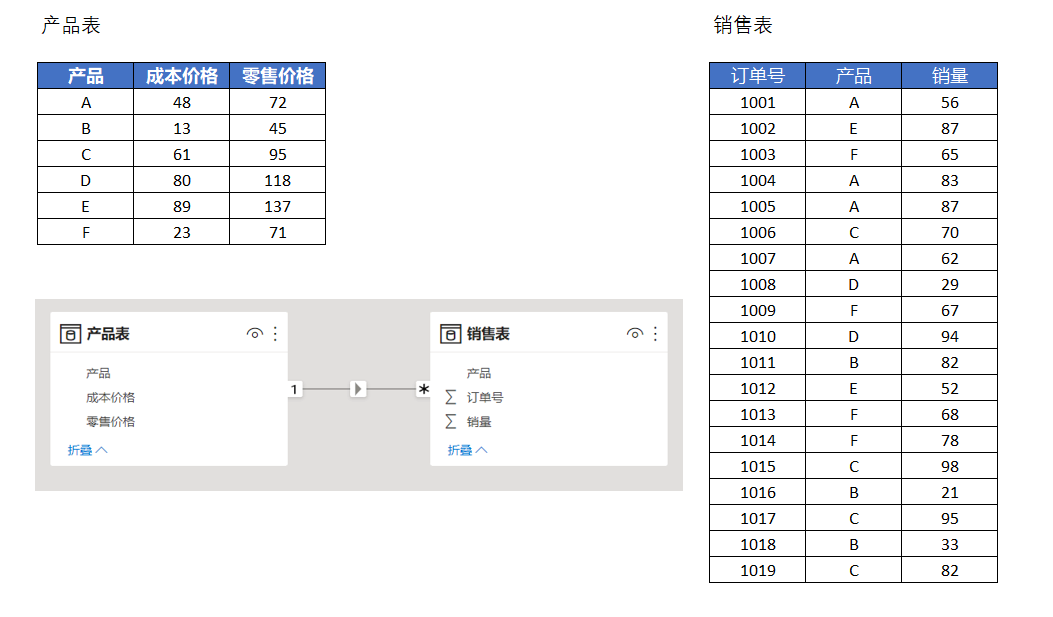
使用到的计算列公式如下:
零售价格 = RELATED('产品表'[零售价格])
零售价格2 =
VAR CurProduct = '销售表'[产品]
RETURN
CALCULATE(SUM('产品表'[零售价格]),'产品表'[产品]=CurProduct)
零售价格3 = CALCULATE(SUM('产品表'[零售价格]))结果如下图所示:
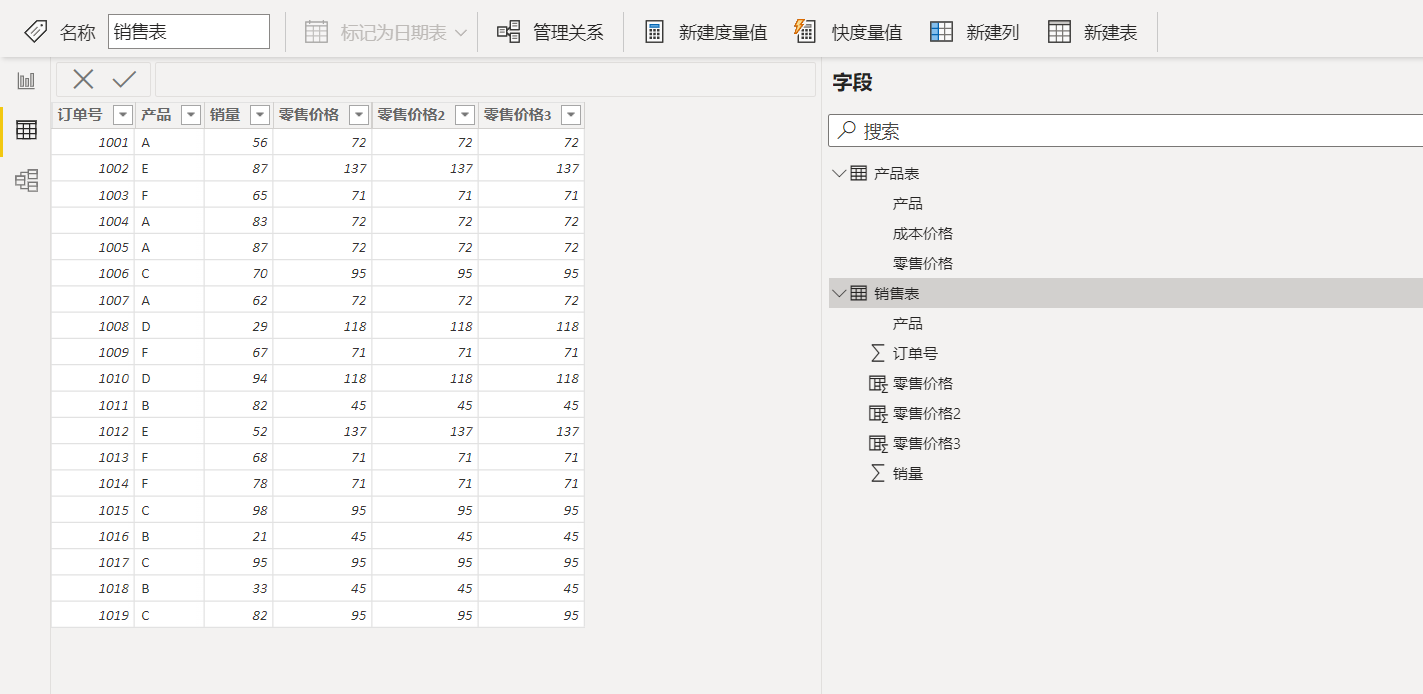
这三个写法的结果都是一样的,其中,RELATED函数允许我们访问基础表的扩展表,刚好,销售表的扩展表就包含了产品表的所有列,所以可以直接获取到对应产品的零售价格;而如果不使用RELATED函数,那么正常的思路就是通过在产品表中进行筛选,找到与销售表当前行的产品对应的数据,然后获取零售价格。根据这个思路,可以写出零售价格2这个公式,那么结果也跟预期的一致。
但为什么零售价格3这个公式里把内部筛选器去掉了结果也一样呢?这是因为当某个基础表被用作筛选器参数或者该基础表的行上下文被转换成筛选上下文后,其扩展表上不属于基础表自身列的其他列也会设置筛选器。下面以订单号为1001(销售表第一行)中的零售价格3的计算过程为例,简单描述下它的计值流程(假设只新建了零售价格3这一个计算列):
- 其所处的计值环境只有基础表提供的行上下文
- 行上下文遇到CALCULATE函数进行了转换,生成了一组筛选器,其中橙色部分是销售表的扩展表上设置的筛选器,具体如下:

- 由于筛选器不能逆着关系箭头的指向逆向筛选,或者说产品表的扩展表不包含销售表的列,因此属于销售表自身的列(蓝色部分)上的筛选器并不能筛选到产品表,只有橙色部分的筛选器才能筛选到产品表并且其筛选的产品与销售表当前行的产品一致
- 产品表被上述筛选器组合筛选后的可见数据如下:
- 由于产品表的可见数据只有一行,因此使用任意聚合函数(SUM、MAX、MIN等)均可获取到相应的零售价格,即72


3、单层行上下文转换时的筛选器交互
前面的例子都是在计算列里演示的,因为计算列的初始计值环境恰好只有基础表提供的行上下文,方便举例与理解。但如果在一个已经具有筛选器的计值环境下发生行上下文转换,那么转换而来的筛选器与原本就存在的筛选器之间的交互又是如何的呢?
答案很简单,遵循筛选器交互的最基本原则,那就是非相同列的筛选器为相交,相同列的筛选器则用后执行的覆盖前面的。其中,行上下文转换而来的筛选器较后执行。那下面用一个简单的小例子来验证一下,用到的度量值如下:
产品所对应订单的销量 = CONCATENATEX(ALL('销售表'[订单号]),CALCULATE(SUM('销售表'[销量]))," | ")
所有订单的销量 = CONCATENATEX(ALL('销售表'[订单号],'销售表'[产品]),CALCULATE(SUM('销售表'[销量]))," | ")新建一个矩阵,行标签为销售表的产品字段,将上面两个度量值放入矩阵中,结果如下:

对第一个度量值来说,由于ALL函数只返回全部订单号所形成的单列表,因此当发生行上下文转换时,转换而来的订单号筛选器将与行标签提供的产品筛选器相交,所以只有行标签所显示的产品对应的订单才有值,不属于行标签的产品的订单对应的值将为空。
而对第二个度量值来说,因为ALL函数返回了全部订单号与产品形成的表,当发生行上下文转换时将得到两个筛选器,一个是订单号的筛选器,另一个则是产品的筛选器,那么在与外部的行标签提供的产品筛选器交互时,转换而来的产品筛选器将覆盖行标签的产品筛选器,因此在迭代计算的过程中,行标签的产品筛选器将影响不了计值环境,因此第二个度量值的所有订单都能够计算出对应的销量。
单层行上下文的转换是很简单的,只要清楚地知道行上下文转换后所得到的筛选器有哪些即可,剩下的无非就是筛选器的交互与修改,以及筛选上下文的生成罢了,而筛选上下文的相关内容在之前的文章中也详细介绍过了,相信都难不倒大家。
行上下文嵌套时的行上下文转换
想要彻底掌握行上下文嵌套时的行上下文转换,是需要一些前置知识的,比如:筛选器的交互方式、CALCULATE函数的计值流程、扩展表原理、行上下文嵌套等等。如果已经掌握了所有的前置知识,那么理解起来就非常简单了。
在正式开始介绍之前,先来回顾一下上篇文章中介绍的多层行上下文嵌套时的嵌套规则:
行上下文嵌套是指在同一个计值环境里同时存在多层行上下文,这些行上下文可能是来自相同表,但也有可能是来自不同的表。
行上下文其实是一组索引标记的集合,DAX引擎会根据其中的索引标记去获取对应列的对应值。当某个计值环境存在多个行上下文时,某个列在每个行上下文里的索引标记都有可能不同,那么就会出现歧义,即DAX引擎不知道该使用哪个索引标记去获取值。因此,DAX引擎需要一套嵌套规则去处理行上下文嵌套时的各种情况。
而行上下文的嵌套规则也很简单,即:相同列的索引标记中,后添加的具有最高引用优先级,将屏蔽或覆盖原有的索引标记;非相同列的索引标记则共存,体现为向前一个层级递补;其中,第一个添加的行上下文位于最外层,越后添加的行上下文位于的层级越靠里面,最后添加的行上下文为最内层,即第0层,倒数第二个添加的行上下文为第1层,倒数第三个添加的行上下文为第2层,以此类推。如下图所示:
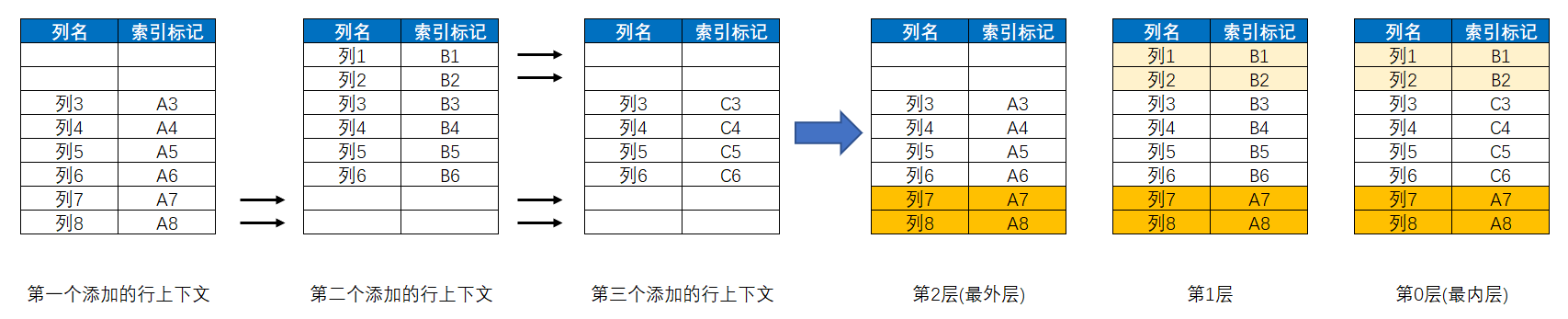
当存在多层行上下文嵌套时,如果发生了行上下文转换,那么所有层级的行上下文都会进行转换,而不是仅仅只转换某一层。但在转换时的执行顺序是有先后的,将按照从外到内,依次从最外层的行上下文开始转换,直到最内层行上下文转换完毕。
那么在这个转换的过程中,转换而来的筛选器依然遵守筛选器交互的最基本原则,即非相同列的筛选器为相交,相同列的筛选器则用后执行的覆盖前面的。因此,层级越靠内的行上下文由于越后执行转换,其转换而来的筛选器将具有一定的优势,最内层的行上下文转换而来的筛选器则能够完全保留。所以很多人都错以为多层行上下文嵌套时的行上下文转换是仅转换最内层的行上下文,这个理解方式是错误的,如果你现在的理解方式就是这种,那么最好马上更正过来。
值得注意的是,由行上下文转换而来的筛选器也有可能会不遵守筛选器交互的最基本原则,例如某层行上下文中使用了KEEPFILTERS函数,那么其转换而来的全部筛选器的交互方式将变为相交。但只要按照行上下文转换的顺序,依次的处理每个筛选器的交互即可保证不出错。
哪怕是多层行上下文嵌套时的行上下文转换,它的规则也可以说是很简单的了,但由于每一层的行上下文具有的字段可能都不一致,导致在最后转换完毕时的计值环境中的筛选器可能会来自多个层级。另外,行上下文通常是由迭代函数提供的,在迭代的时候行上下文也会相应的变化。两者叠加,就凭空增加了亿点点难度,需要有一定的空间想象力才能驾驭得住。
那下面就通过一个简单的案例来熟悉一下这种多层级的转换过程,用到的数据与模型如下图:

现在需要统计每个产品的销量,并把销冠产品(销量最大的产品)的销量单独显示出来,具体效果如下图所示:

这个问题的解决思路很简单,只要判断当前行标签的产品的销量是否等于最大销量,若等于就显示相应的销量,否则为空。因此最佳的解决方法就是使用IF函数来求解,但这样的话就失去其意义了,因此我们采用FILTER函数的第二参数来进行判断,人为的增加亿点难度。
首先,来看一个错误的写法,用到的度量值如下:
销量 = SUM('订单表'[数量])
销冠产品的销量-Wrong =
CALCULATE(
[销量],
FILTER(
VALUES('产品表'[产品代码]),
[销量]=MAXX(ALL('产品表'[产品代码]),[销量])
)
)结果如下图:
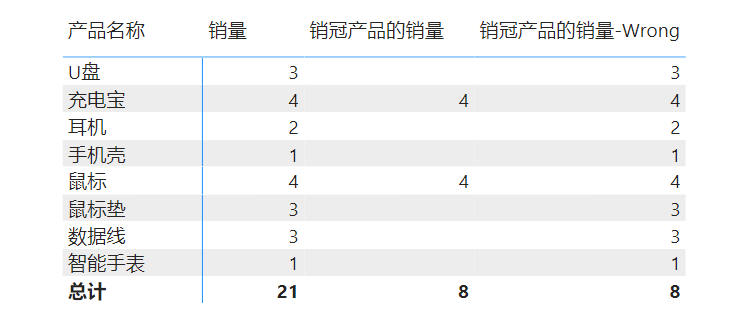
上面这个错误的写法只有两层的行上下文嵌套,并不会太复杂,而且两层的嵌套还是很常见的。那么下面来分析一下,这个写法为何不能得到正确结果。

首先,行标签提供了一个产品名称的筛选器,然后VALUES被其筛选,返回相应的产品代码,此时如果FILTER第二参数为真,那么VALUES返回的产品代码将成为CALCULATE的内部筛选器并与行标签的产品名称筛选器相交,由于产品名称与产品代码相对应,因此必然能够返回当前行标签的产品的销量;若FILTER第二参数为假,那么FILTER将返回空,使得最终结果为空。
因此,整个逻辑的最核心部分就是FILTER的第二参数,如果能够在行标签为销冠产品时让FILTER第二参数为真,其它产品为假,那么将达到案例所需的效果。
对于上图标注的第一个销量度量值来说,其所处的计值环境有行标签提供的产品名称筛选器,以及FILTER提供的行上下文,当其开始计值时,行上下文转换得到一个产品代码筛选器,将与行标签提供的产品名称筛选器相交,由于产品名称与产品代码相对应,因此返回当前行标签的产品对应的销量。
对于上图标注的第二个销量度量值来说,其所处的计值环境有行标签提供的产品名称筛选器、FILTER提供的行上下文,以及MAXX提供的行上下文。当其开始计值时,两层行上下文都将发生转换,但MAXX提供的行上下文较后执行,且FILTER与MAXX的行上下文转换后的筛选器均为产品代码列上的筛选器,因此MAXX提供的行上下文转换后得到的产品代码筛选器将覆盖由FILTER提供的行上下文转换而来的产品代码筛选器,然后再与行标签提供的产品名称筛选器相交。因此在MAXX函数迭代的过程中,只有与行标签的产品名称相对应的产品代码才会有值,其它的则为空,因此MAXX最终返回的其实就是当前行标签的产品对应的销量。
所以FILTER第二参数其实是恒成立的,使得所有行标签都能够计算到对应的销量。
经过上面的梳理,已经成功找到了这个错误写法之所以错误的原因了,那就是FILTER第二参数恒成立了,达不到筛选的效果,但最根本的原因其实还是MAXX函数在迭代过程中无法找到所有产品的最大值,因为其受到了行标签提供的产品名称筛选器的影响。既然找到原因了,那么修改起来也就有了针对性,只要在MAXX函数的计值环境中把行标签提供的产品名称筛选器移除即可,具体如下:
销冠产品的销量-Correct =
CALCULATE(
[销量],
FILTER(
VALUES('产品表'[产品代码]),
[销量]=MAXX(ALL('产品表'[产品代码]),CALCULATE([销量],ALL('产品表'[产品名称])))
)
)结果如下图:
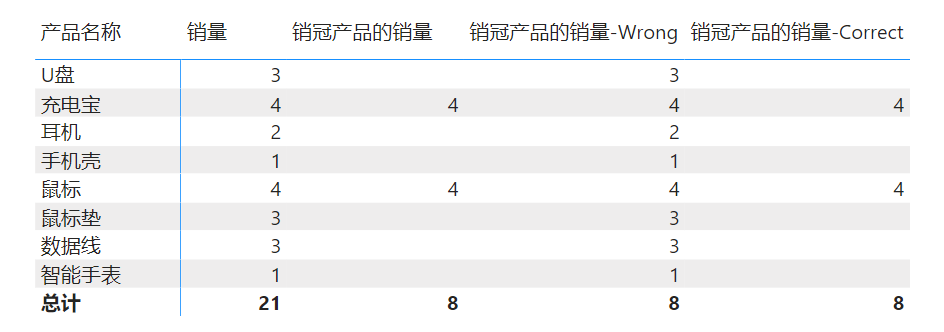
那么这个案例到这里就结束了,更多的细节部分就留给你们探索,下面给出一些该案例的错误写法与正确写法,仅供参考:
错误写法:
销冠产品的销量-Wrong1 = CALCULATE([销量],FILTER(ALL('产品表'),[销量]=MAXX(ALL('产品表'[产品代码]),[销量])))
销冠产品的销量-Wrong2 = CALCULATE([销量],FILTER(ALL('产品表'[产品代码]),[销量]=MAXX(ALL('产品表'[产品代码]),[销量])))
销冠产品的销量-Wrong3 = CALCULATE([销量],FILTER(VALUES('产品表'[产品代码]),[销量]=MAXX(ALL('产品表'[产品代码]),[销量])))
销冠产品的销量-Wrong4 = CALCULATE([销量],FILTER(ALL('产品表'),[销量]=MAXX(ALL('产品表'),[销量])))正确写法:
销冠产品的销量-Correct1= CALCULATE([销量],FILTER('产品表',[销量]=MAXX(ALL('产品表'),[销量])))
销冠产品的销量-Correct2 = CALCULATE([销量],FILTER(VALUES('产品表'[产品代码]),[销量]=MAXX(ALL('产品表'[产品代码]),CALCULATE([销量],ALL('产品表'[产品名称])))))
销冠产品的销量-Correct3 = CALCULATE([销量],FILTER(VALUES('产品表'[产品名称]),[销量]=MAXX(ALL('产品表'[产品名称]),[销量])))
销冠产品的销量-Correct4 = CALCULATE([销量],KEEPFILTERS(FILTER(ALL('产品表'),[销量]=MAXX(ALL('产品表'),[销量]))))在该框架下,你还能写出更多的错误写法与正确写法吗?
与行上下文转换相关的知识点基本上都介绍完了,并且也通过一些简单的例子去验证了,剩下的就看个人的领悟以及实践了。另外,如果遇到了复杂的行上下文嵌套与转换,大脑一下子转不过弯来,那么建议手写一下各个函数的计值环境与计值流程,一步一步地梳理清楚,这比凭空想象会更有帮助。
DAX系列文章中涉及到的案例文件,均已上传到QQ群:344353627,若有需要,可自行加群获取。