夕枫 | 笔绘人生
夕枫 | 笔绘人生在上篇文章里,已经介绍了行上下文的真正指代:“ 表中各列在某一行的索引标记的集合 ”,并且给出了对行上下文的最佳理解方式:“ 忽略DAX引擎内部对行上下文的转换与处理,直接把行上下文简单理解成正在计算的当前行的所有数据 “,那么本篇文章就将基于此行上下文的最佳理解方式来介绍行上下文的嵌套。
行上下文的嵌套规则
行上下文嵌套是指在同一个计值环境里同时存在多层行上下文,这些行上下文可能是来自相同表,但也有可能是来自不同的表。
行上下文其实是一组索引标记的集合,DAX引擎会根据其中的索引标记去获取对应列的对应值。当某个计值环境存在多个行上下文时,某个列在每个行上下文里的索引标记都有可能不同,那么就会出现歧义,即DAX引擎不知道该使用哪个索引标记去获取值。因此,DAX引擎需要一套嵌套规则去处理行上下文嵌套时的各种情况。
而行上下文的嵌套规则也很简单,即:相同列的索引标记中,后添加的具有最高引用优先级,将屏蔽或覆盖原有的索引标记;非相同列的索引标记则共存,体现为向前一个层级递补;其中,第一个添加的行上下文位于最外层,越后添加的行上下文位于的层级越靠里面,最后添加的行上下文为最内层,即第0层,倒数第二个添加的行上下文为第1层,倒数第三个添加的行上下文为第2层,以此类推。如下图所示:
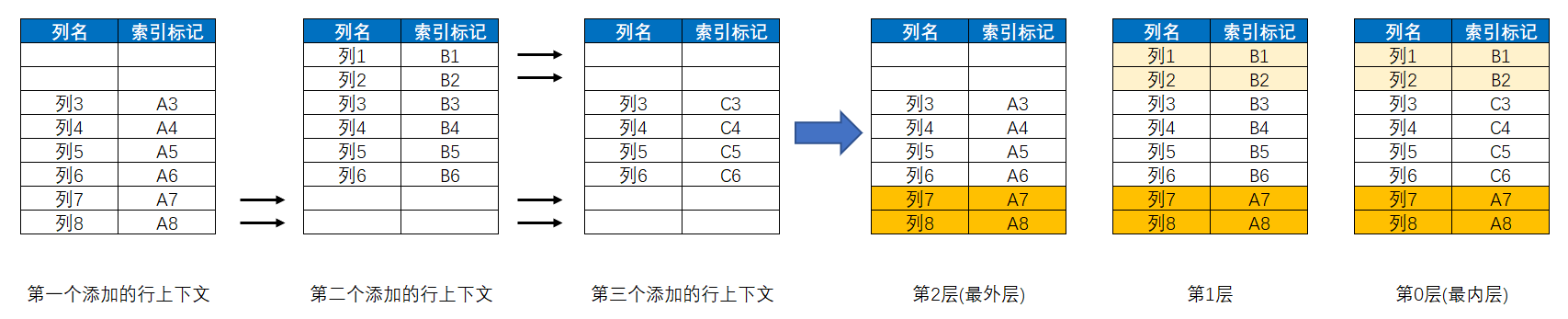
在上图中,计值环境里总共添加了三个行上下文,因此就具有三层的行上下文嵌套结构。其中,最内层行上下文里的索引标记具有最高引用优先级,即DAX引擎会默认使用各列在最内层的索引标记来获取数据,但我们也可以让DAX引擎使用指定层级里的索引标记来获取数据,只需要使用EARLIER函数明确指定所要使用的层级即可。
下面简单介绍下EARLIER函数的使用:
EARLIER函数:
- 语法:
EARLIER(column, number)- 作用:
使用第二参数所指定的行上下文层级中的索引标记来获取第一参数所指定列的对应值,其中第二参数接受一个大于0的整数,代表行上下文的层级,第二参数可省略,默认为1。
以上图中的三层行上下文结构为例,简单介绍下EARLIER函数的使用:
- 获取列3在最内层行上下文所对应的值:’TableName'[Column3],等于:C3
- 获取列3在最1层行上下文所对应的值:EARLIER( ‘TableName'[Column3] ),等于:B3
- 获取列3在最外层行上下文所对应的值:EARLIER( ‘TableName'[Column3] , 2 ),等于:A3
EARLIER函数的使用比较简单,就不再赘述。此外,DAX中还有一个EARLIEST函数,这个函数不能指定层级,但能直接获取最外层行上下文所对应的数据,在三层或以上的行上下文嵌套中才有用武之地,但一般都是以两层行上下文嵌套出现最多,很少使用三层或以上的行上下文嵌套,因此EARLIEST函数很少用到,这里就简单了解下。
一些帮助理解的例子
使用到的数据与数据模型如下图所示:
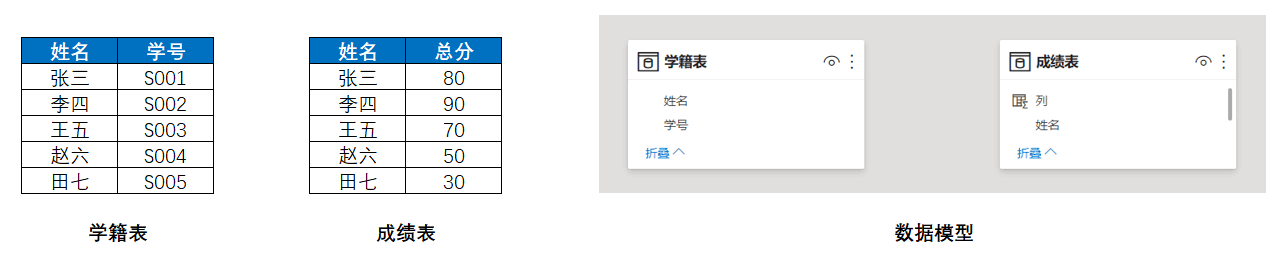
先来看第一个例子,在成绩表里添加一个计算列,使用到的计算列表达式如下:
总分放大五倍 = SUMX('学籍表','成绩表'[总分])结果如下图所示:

下面简单介绍下该计算列在第一行的值400的计值流程:
- 外部计值环境中存在一个由成绩表提供的行上下文,可表示成如下:
{'成绩表'[姓名]="张三",'成绩表'[总分]=80} - 由于外部计值环境里不存在任何筛选器,因此SUMX第一参数的表达式返回了学籍表的所有数据,共5行,然后DAX引擎为学籍表的每一行创建行上下文。
-
SUMX迭代学籍表第一行时的计值环境存在两层行上下文嵌套,可表示成如下:
{'成绩表'[姓名]="张三",'成绩表'[总分]=80} // 第1层 {'成绩表'[姓名]="张三",'成绩表'[总分]=80,'学籍表'[姓名]="张三",'学籍表'[学号]=S001} // 第0层 // 只有表名与列名均一致的列才是相同列,因此'学籍表'[姓名]的索引标记并不会屏蔽或覆盖'成绩表'[姓名]的索引标记,而是共存 - 然后SUMX第二参数直接引用了成绩表中的总分列,默认使用最内层行上下文,因此SUMX在迭代学籍表第一行时的结果为80
-
然后SUMX继续迭代学籍表的第二行,此时同样存在两层行上下文嵌套,可表示成如下
{'成绩表'[姓名]="张三",'成绩表'[总分]=80} // 第1层 {'成绩表'[姓名]="张三",'成绩表'[总分]=80,'学籍表'[姓名]="李四",'学籍表'[学号]=S002} // 第0层 - 虽然SUMX提供的行上下文变化了,但是由成绩表提供的行上下文并没有改变,因此SUMX在迭代学籍表第二行时的结果也为80
- SUMX继续迭代剩余的行,在每一行中,第二参数所得到的结果都为80
- 在迭代完成后,SUMX把第二参数在每一行所得到的结果都累加起来,因为共有5行,因此最终结果就是400
下面再来看第二个例子,在成绩表里再添加一个计算列,使用到的计算列表达式如下:
总分放大五倍-EARLIER = SUMX('学籍表',EARLIER('成绩表'[总分]))结果如下图所示:
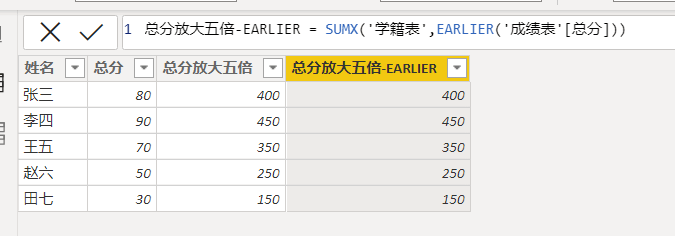
下面同样来看下该计算列在第一行的值400的计值流程:
- 外部计值环境中存在一个由成绩表提供的行上下文,可表示成如下:
{'成绩表'[姓名]="张三",'成绩表'[总分]=80,'成绩表'[总分放大五倍]=400} - 由于外部计值环境里不存在任何筛选器,因此SUMX第一参数的表达式返回了学籍表的所有数据,共5行,然后DAX引擎为学籍表的每一行创建行上下文。
-
SUMX迭代学籍表第一行时的计值环境存在两层行上下文嵌套,可表示成如下:
{'成绩表'[姓名]="张三",'成绩表'[总分]=80,'成绩表'[总分放大五倍]=400} // 第1层 {'成绩表'[姓名]="张三",'成绩表'[总分]=80,'成绩表'[总分放大五倍]=400,'学籍表'[姓名]="张三",'学籍表'[学号]=S001} // 第0层 - 然后SUMX第二参数引用了成绩表中的总分列,并使用EARLIER函数指定使用第1层行上下文,因此SUMX在迭代学籍表第一行时的结果为80
- SUMX继续迭代剩余的行,在每一行中,第二参数所得到的结果都为80
- 在迭代完成后,SUMX把第二参数在每一行所得到的结果都累加起来,因为共有5行,因此最终结果就是400
在第二个例子中,虽然使用了EARLIER函数指定使用第1层行上下文,但结果其实与直接引用列(默认使用最内层行上下文)时相同,因为SUMX提供的行上下文中并不存在成绩表各列的索引标记,因此外层行上下文(成绩表的行上下文)中的索引标记将递补进入最内层行上下文,所以成绩表的总分列在两层行上下文中的索引标记都相同,故无论是否使用EARLIER函数,所获取到的数据都将一样,所以上面提到的两个计算列公式等价。
下面再来看第三个例子,这个例子主要是为了与第二个例子做对比。同样是在成绩表里再添加一个计算列,所用到的计算列表达式如下:
错误用法 = SUMX('学籍表',EARLIER('学籍表'[姓名]))结果如下图所示:
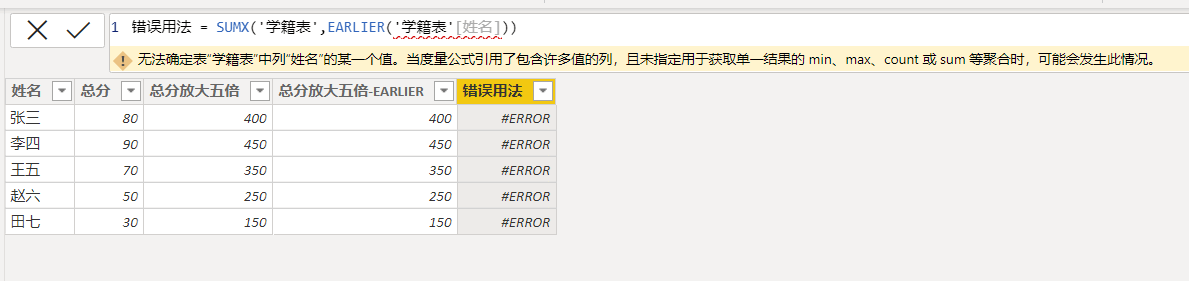
这是错误用法,所以报错是可以遇见的。但为什么会报错呢?根据错误提示,我们可以知道错误的原因是因为DAX引擎无法准确获取学籍表中姓名列的具体某一个值,通常出现这个错误提示都是因为计值环境中的行上下文里不存在指定列的索引标记所导致的。
下面同样来看下该计算列在第一行时的计值流程,逐步地找到报错的原因。
- 外部计值环境中存在一个由成绩表提供的行上下文,可表示成如下(为了方便描述,忽略上两个例子中添加的计算列的索引标记,该忽略行为并不影响计值流程与结果):
{'成绩表'[姓名]="张三",'成绩表'[总分]=80} - 由于外部计值环境里不存在任何筛选器,因此SUMX第一参数的表达式返回了学籍表的所有数据,共5行,然后DAX引擎为学籍表的每一行创建行上下文。
-
SUMX迭代学籍表第一行时的计值环境存在两层行上下文嵌套,可表示成如下:
{'成绩表'[姓名]="张三",'成绩表'[总分]=80} // 第1层 {'成绩表'[姓名]="张三",'成绩表'[总分]=80,'学籍表'[姓名]="张三",'学籍表'[学号]=S001} // 第0层 - 然后SUMX第二参数引用了学籍表中的姓名列,并使用EARLIER函数指定使用第1层行上下文
- 由于第1层行上下文中并不存在学籍表中的姓名列的索引标记,因此DAX引擎无法确定该获取该列的哪一个值,故报错
- 由于报错,后续计值流程中断,返回报错信息
虽然我们可以指定任意层次的行上下文作为计值环境,但想要不出错,还是需要先确定某一层中的行上下文里是否存在所需的索引标记,否则盲目使用将很容易出错。
下面再来看最后一个例子,这个例子需要计算成绩表中总分列按从小到大的累计值,结果如下图所示:
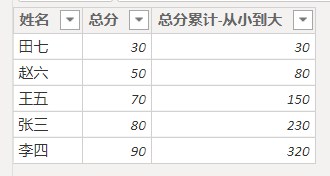
其实计算累计值的思路很简单,先确定按哪个顺序累计,然后找到每一行的累计数据进行累加即可。那么在这个例子中,需要按总分从小到大累计,那么计算的思路就是找到小于等于当前行的总分的那些总分,然后累加即可。具体的计算列公式如下:

这个例子的解决思路与解决方案都已经给出,而且也比较简单,所以具体的计值流程就留给你们自己思考。
行上下文嵌套其实是很简单的,但由于行上下文通常是由迭代函数提供,而迭代函数需要循环迭代表中的每一行且在每一行的行上下文都不一样,同时还要考虑与外层行上下文的嵌套,所以才显得比较抽象、复杂与难懂。但只要遵循我所给出的嵌套规则,并多做一点测试,相信很快就能掌握它!
DAX系列文章中涉及到的案例文件,均已上传到QQ群:344353627,若有需要,可自行加群获取。