夕枫 | 笔绘人生
夕枫 | 笔绘人生前言
数据流是一种基于云的自助式数据准备技术。 数据流使客户能够将数据引入、转换和加载到 Microsoft Dataverse 环境、Power BI 工作区或组织的Azure Data Lake Storage帐户中。简单来说就是一个云端的PowerQuery编辑器加上数据存储,并可以在多个Microsoft产品中使用,比如PowerBI。
数据流会按照PowerQuery Online里定义的步骤去获取与清洗数据,然后把处理好的数据存储在PowerBI云端工作区中,然后PowerBI Desktop里可以像连接数据库一样连接到云端的数据流以使用这些处理好的数据。
使用数据流的好处主要有:
1、提高数据重用性。先看两个实际中比较常发生的场景,对理解数据重用性的含义可能会更有帮助。场景一:假设A数据集里有一个上亿行数据的销售表,然后B数据集里也需要使用这个销售表的数据,那么在B数据集里只能是从数据源里重新获取与处理这部分数据,而不能直接使用A数据集里的销售表;场景二:多个数据集用到了相同的数据,各个数据集的这部分数据都是从数据源里获取并按相同清洗步骤得到的。然后此时业务逻辑发生改变,清洗步骤需要变更,比如筛选条件需要改动,那么此时只能是对每个数据集都进行变更操作,而不能一次更改就自动同步到所有数据集中;基于这两个场景,可以把需要重复使用到的数据放在数据流中,然后每个数据集都直接使用数据流上的数据,集中管理,提高数据的重用性,即使需要更改清洗步骤,那也只需要在数据流上进行一次更改即可,各个数据集不受影响且无需改动。
2、保持数据一致性。所有数据集的相同数据都来自数据流的话,可以保持数据一致性,避免由于清洗步骤中可能存在的人为失误,导致数据与别的数据集不一致的情况。特别是类似金额等的敏感数据,保持所有位置的数据都一致是基本要求,不然容易出现扯皮。
3、降低数据源负载。如果所有数据集的相同数据都是各自从数据源重新获取的,那么就会向数据源发送多次获取数据的请求,而如果改用数据流的话,那么就只有数据流本身会向数据源发送一次获取数据的请求,其它数据集是直接使用数据流上存储的数据,并不会向数据源发送请求,从而可以降低数据源的服务器负载。
数据流的创建与使用
数据流的创建很简单,先在云端工作区里选择新建数据流,如下图所示。
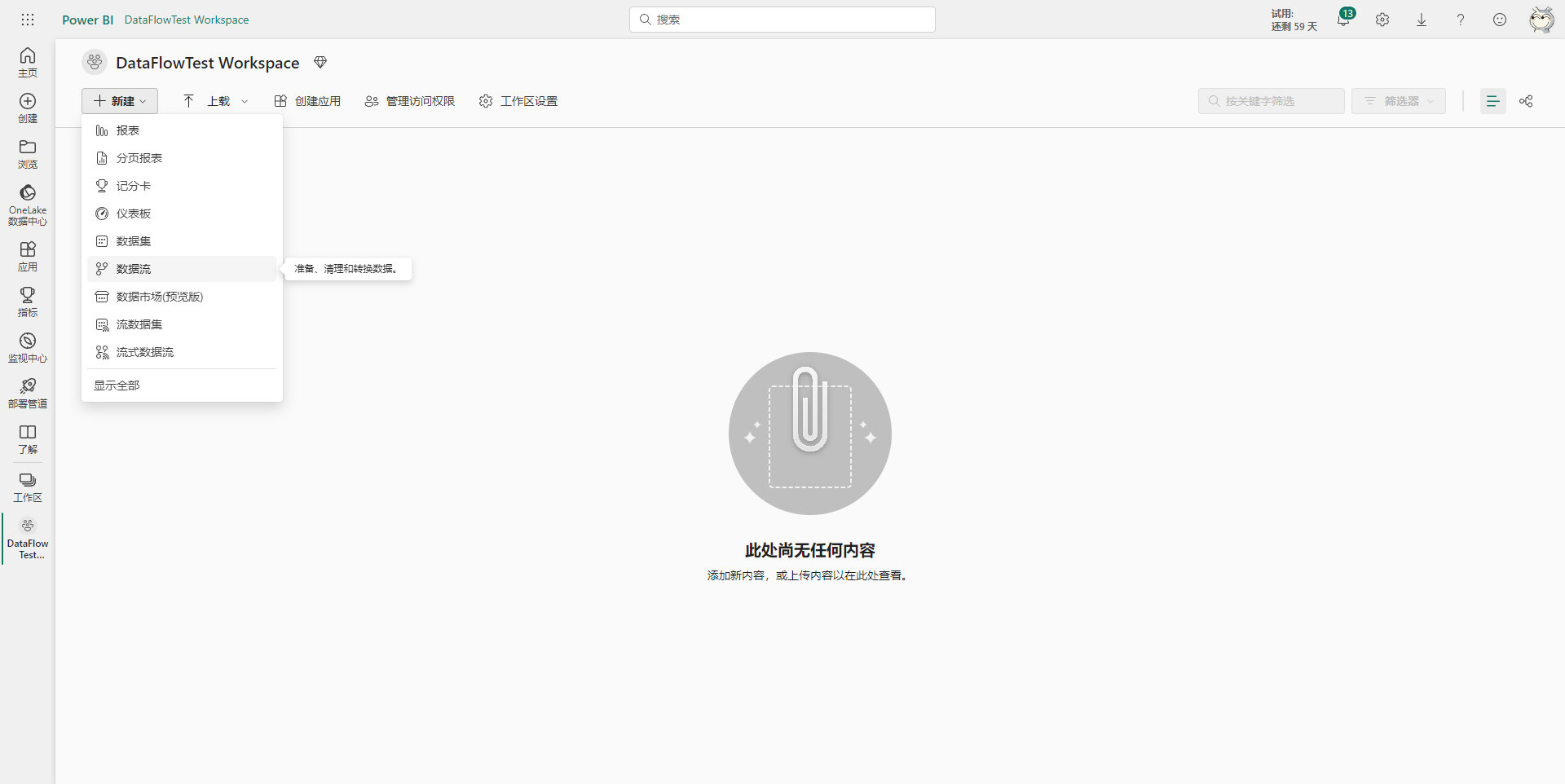
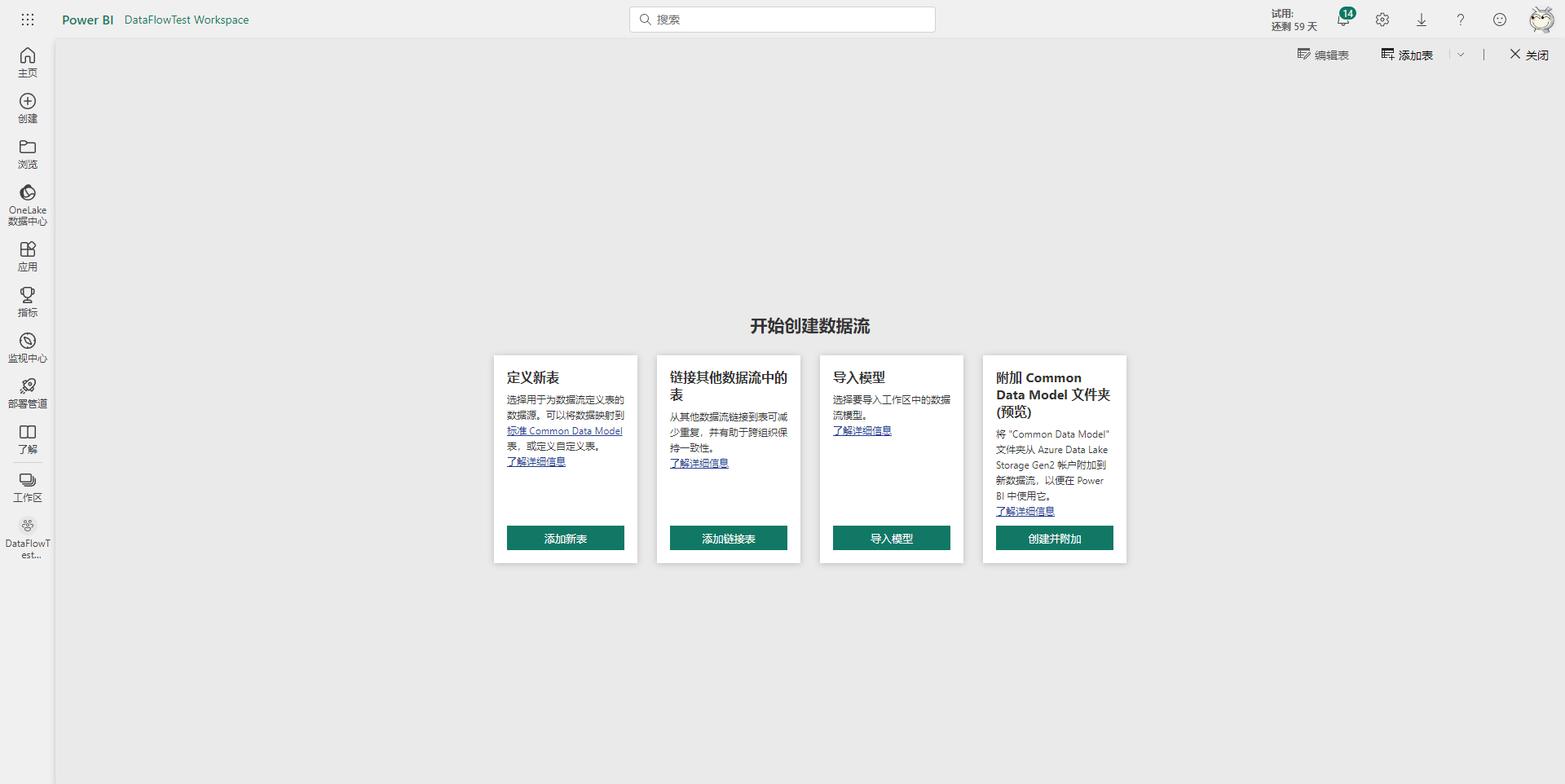
然后在跳转后的页面里有不同的选项,其中添加新表是指从数据源中获取新的数据形成一张新的表;添加链接表是指使用其它数据流中存储的表;导入模型指的是导入之前导出的数据流,主要用于数据流在不同工作区或环境的迁移;最后一个附加CDM文件夹选项是指将ADLS存储账号链接到当前工作区,并将新创建的数据流的数据存储在ADLS中,这涉及到Azure订阅,暂不介绍。下面依次介绍一下前三个选项的使用。
1、添加新表
假如现在新建的数据流需要从数据源中获取新的数据形成一张新的表,那么就需要使用到添加新表功能。
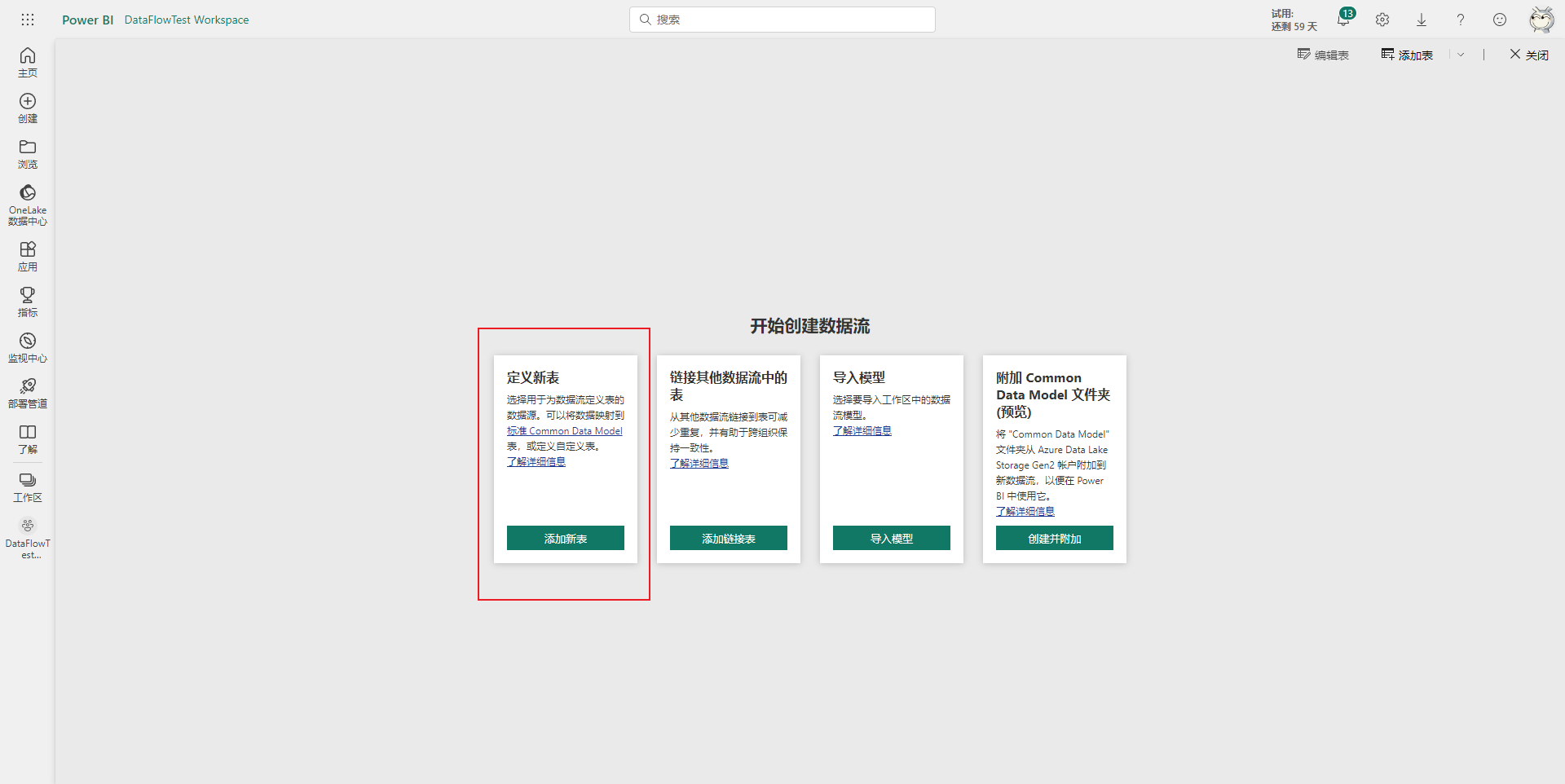
首先点击添加新表按钮,然后在跳转界面选择相应的数据源,比如Excel工作簿。
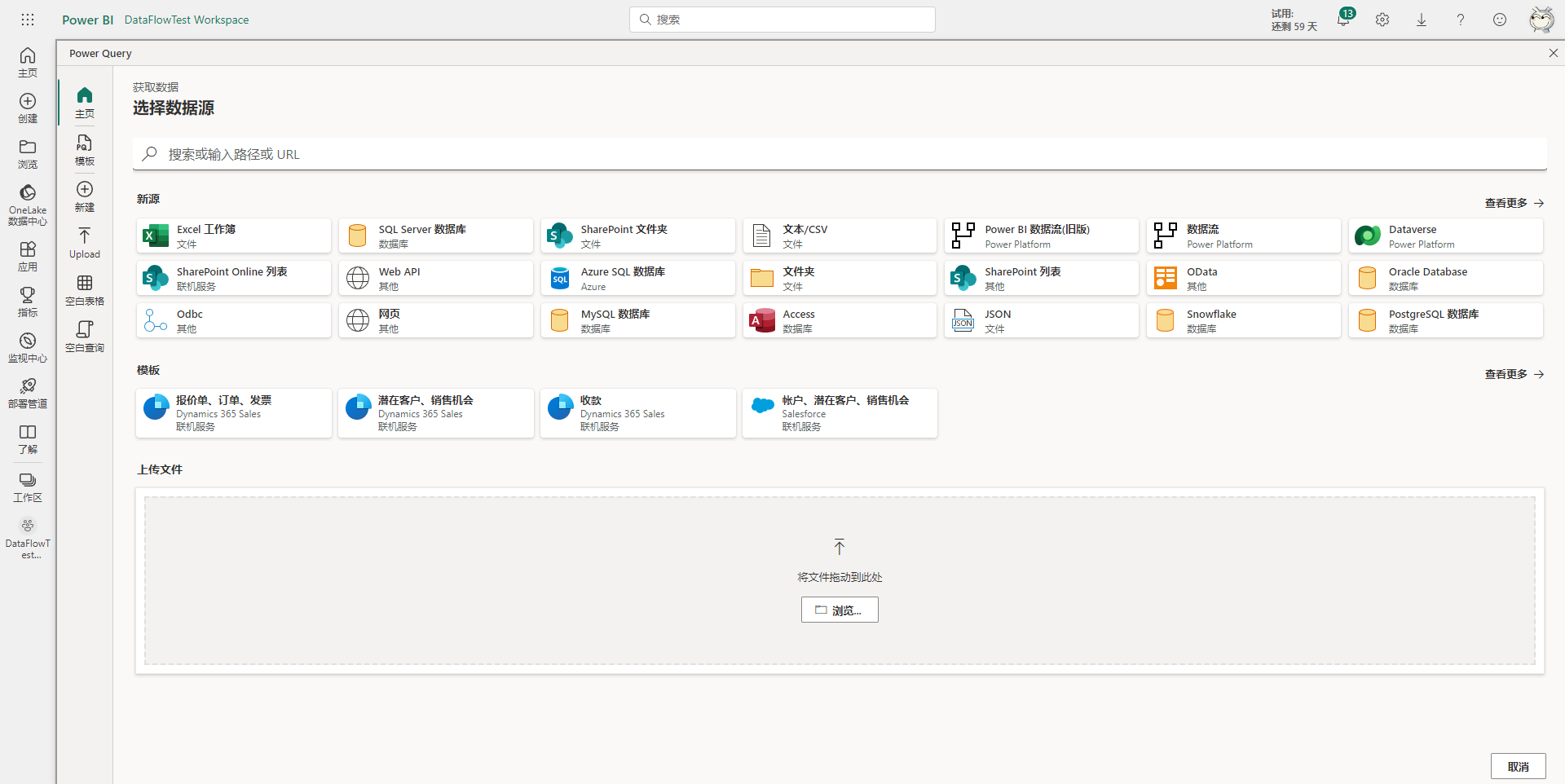
然后输入Excel文件本地路径或网络路径,支持OneDrive。这里选择使用本地Excel文件,因此填写本地Excel文件的所在磁盘路径,然后配置网关等连接凭据即可。
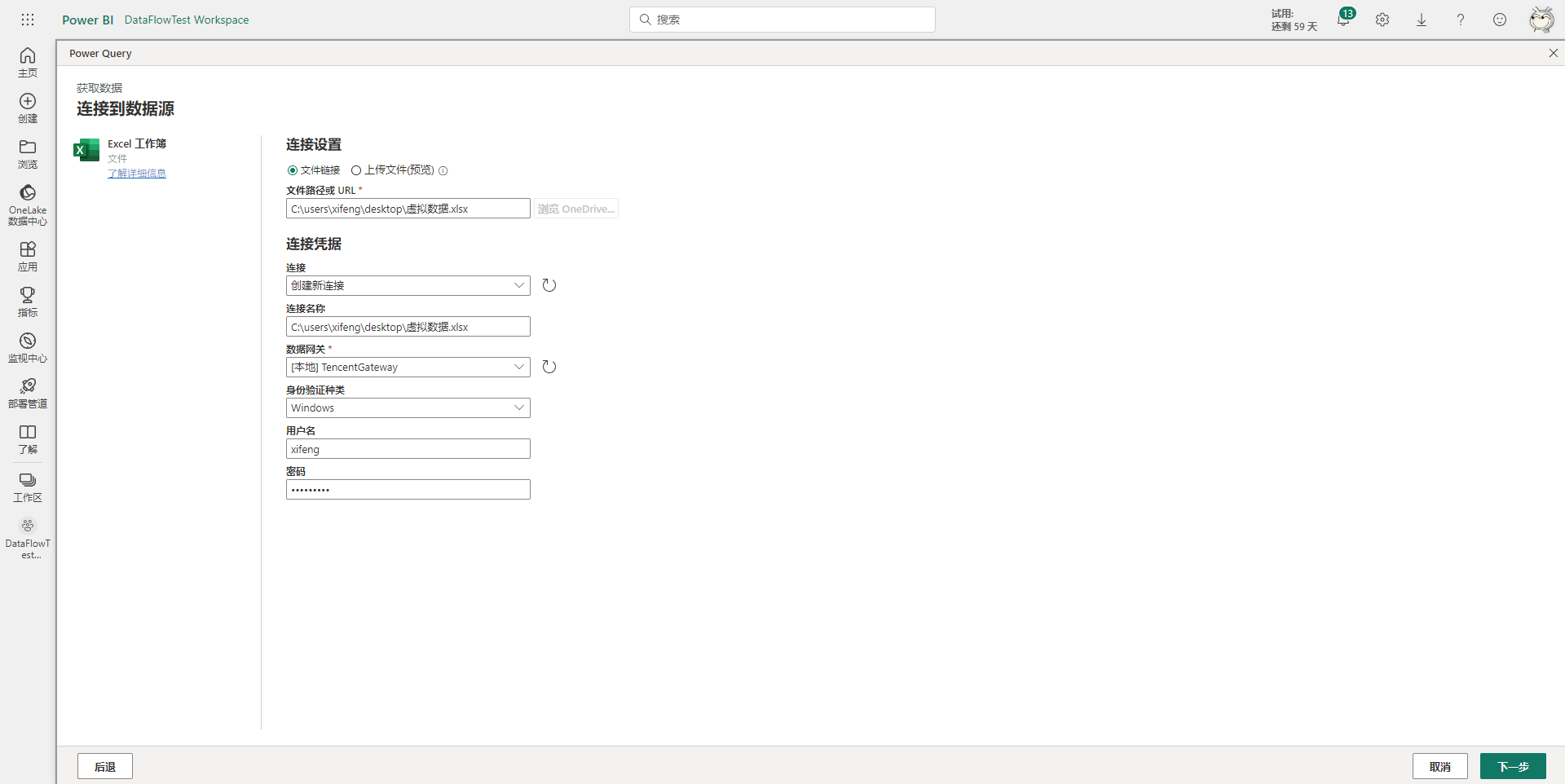
然后下一步则是选择需要导入的表,比如这里只选择订单表。
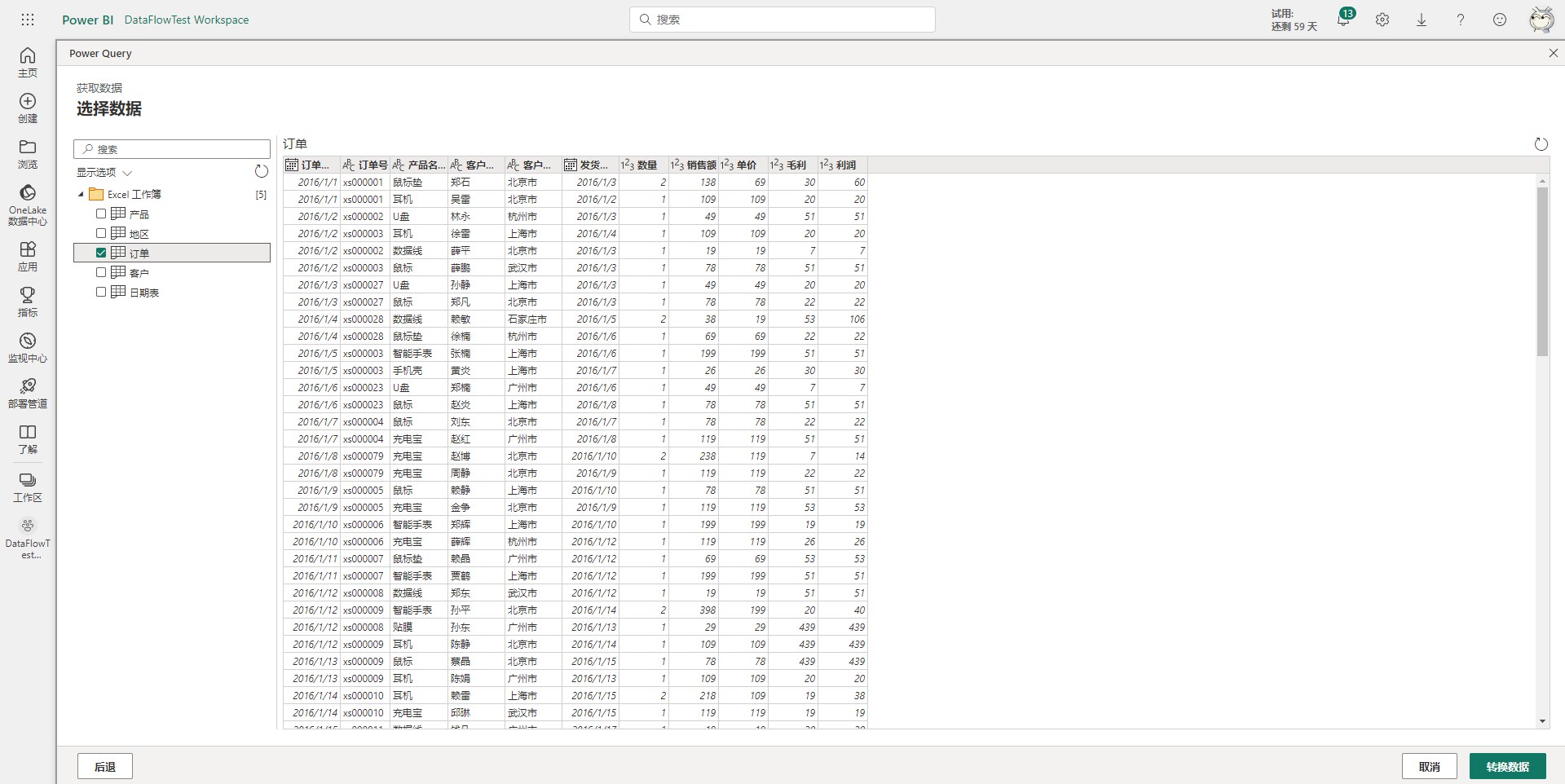
然后点击转换数据即可进入熟悉的PowerQuery界面,如下图所示。与本地PowerQuery的编辑器界面相比,云端的PowerQuery多了一个视图,借助该视图可以方便的观察到各个查询的引用世系,此外其它地方基本一致,因此界面这一块不做更多介绍,可以自行探索。
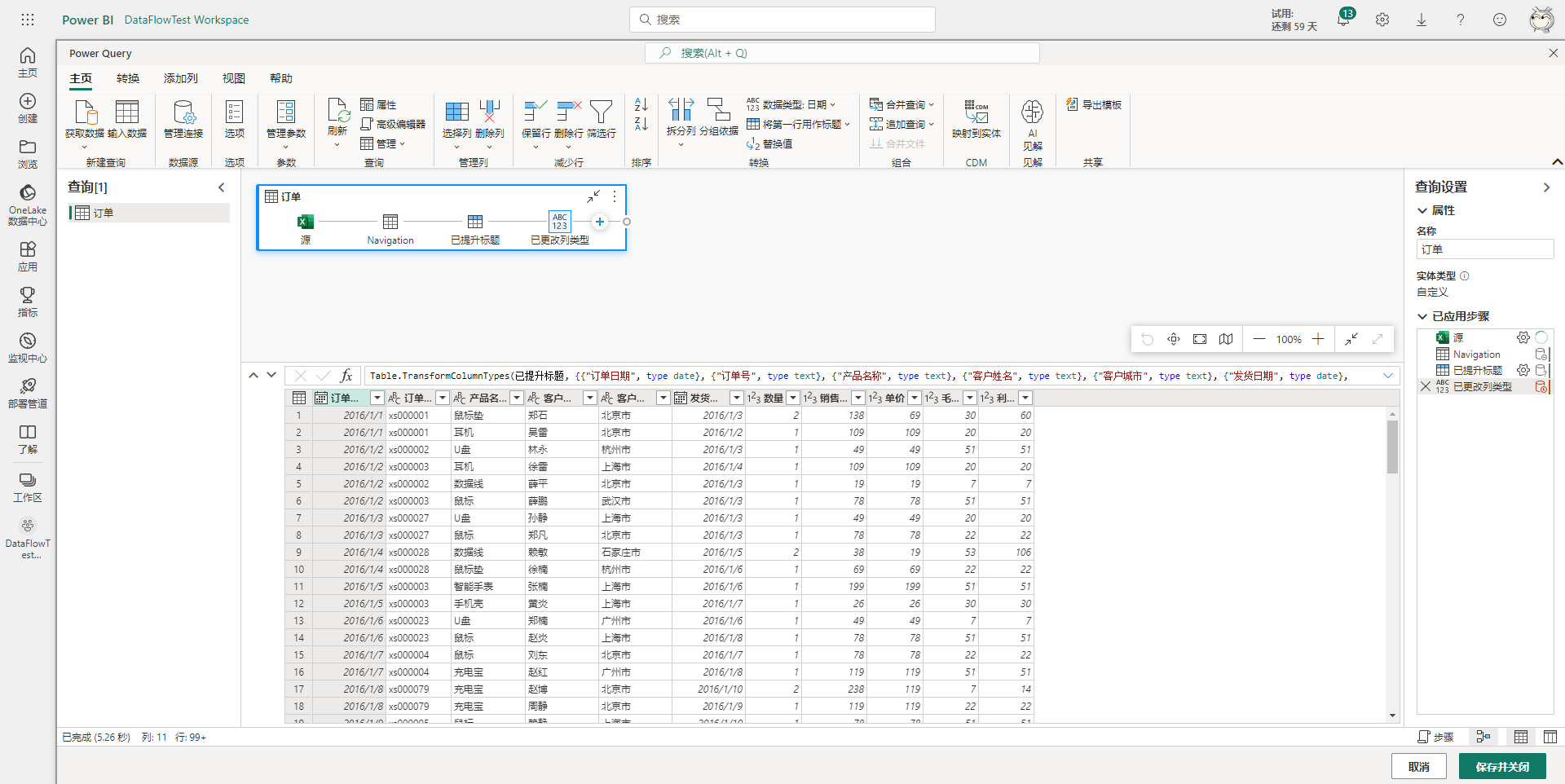
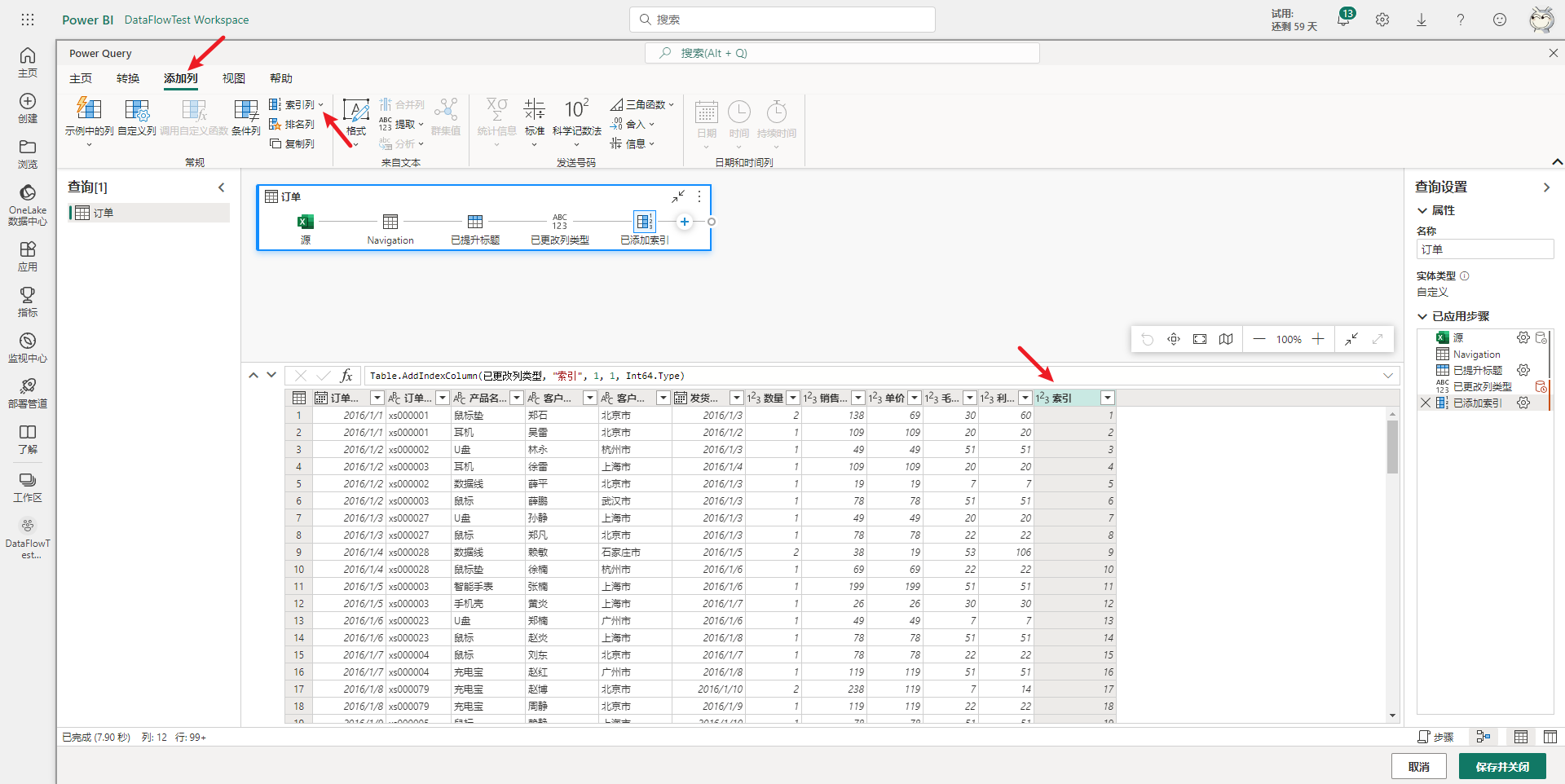
然后可以在上面这个云端化的PowerQuery中进行数据的清洗与处理,比如给订单表添加一个索引列,选择添加列下的索引列选项即可,如下图所示。
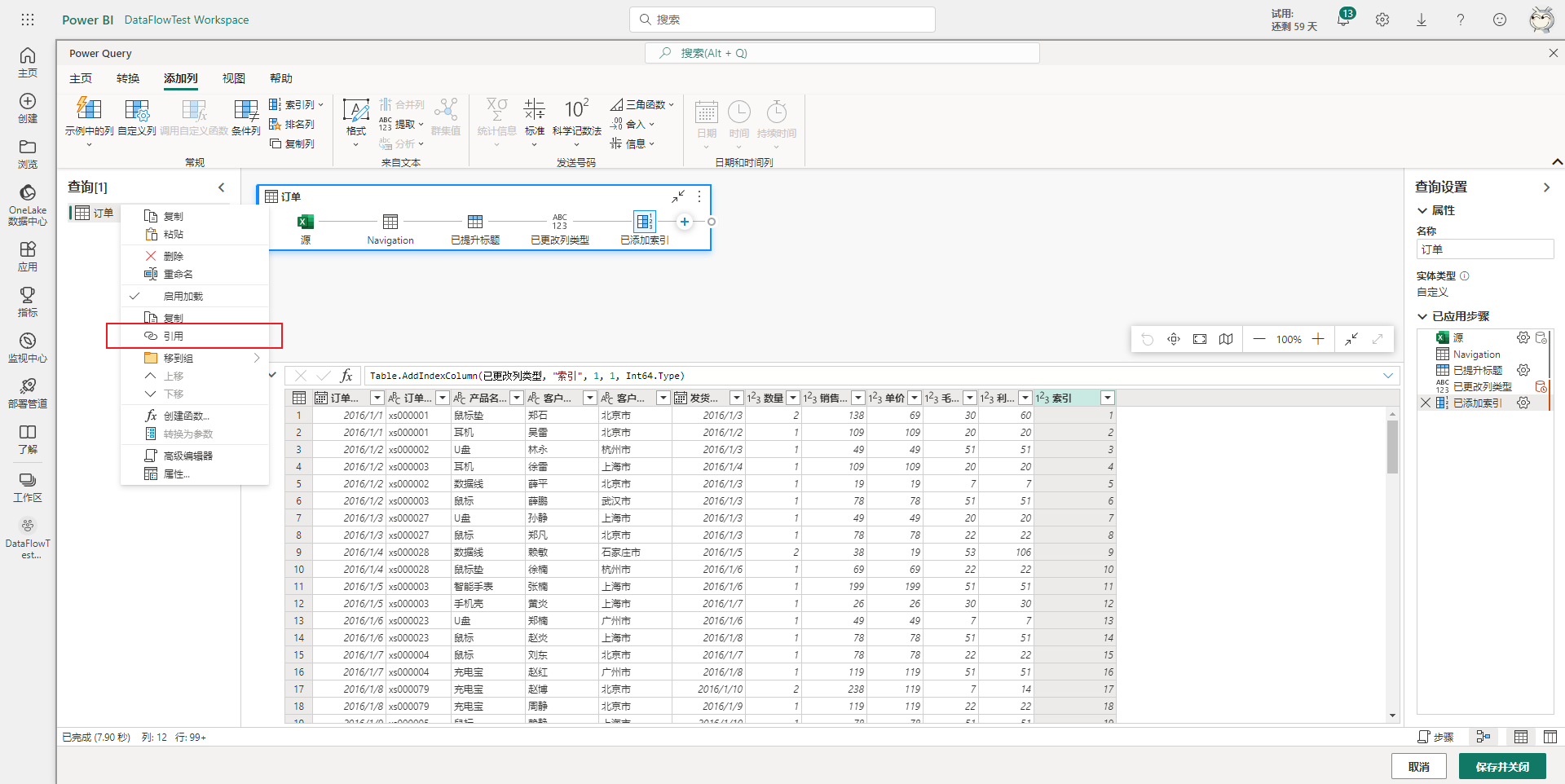
再比如想对订单表进行预聚合,添加一个新的查询来统计各产品的总销量,那么可以先复制或引用订单表生成新的查询,然后再进行分组聚合,比如这里选择引用。
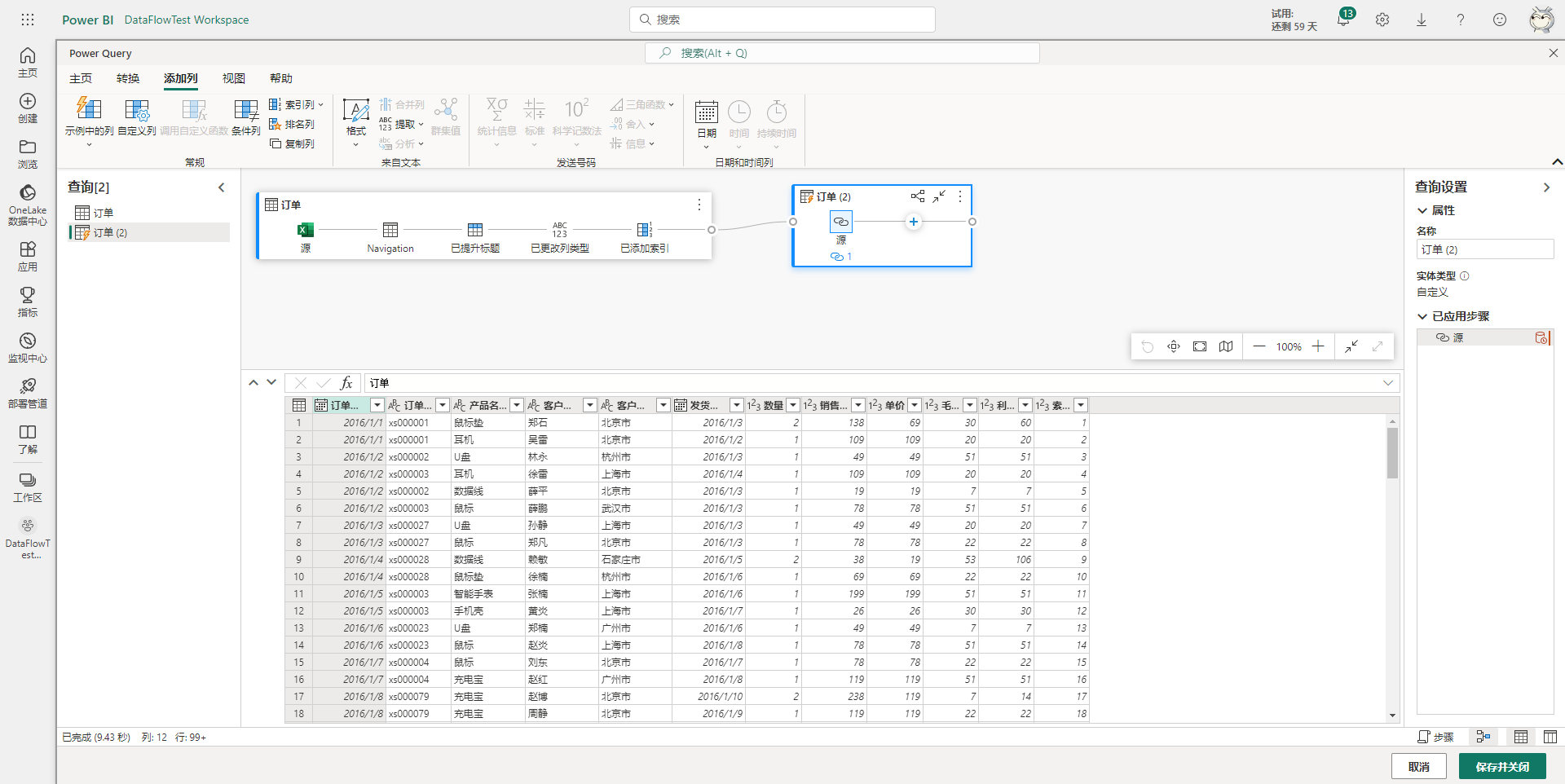
然后会自动添加一个引用订单表的新查询,如下图所示。
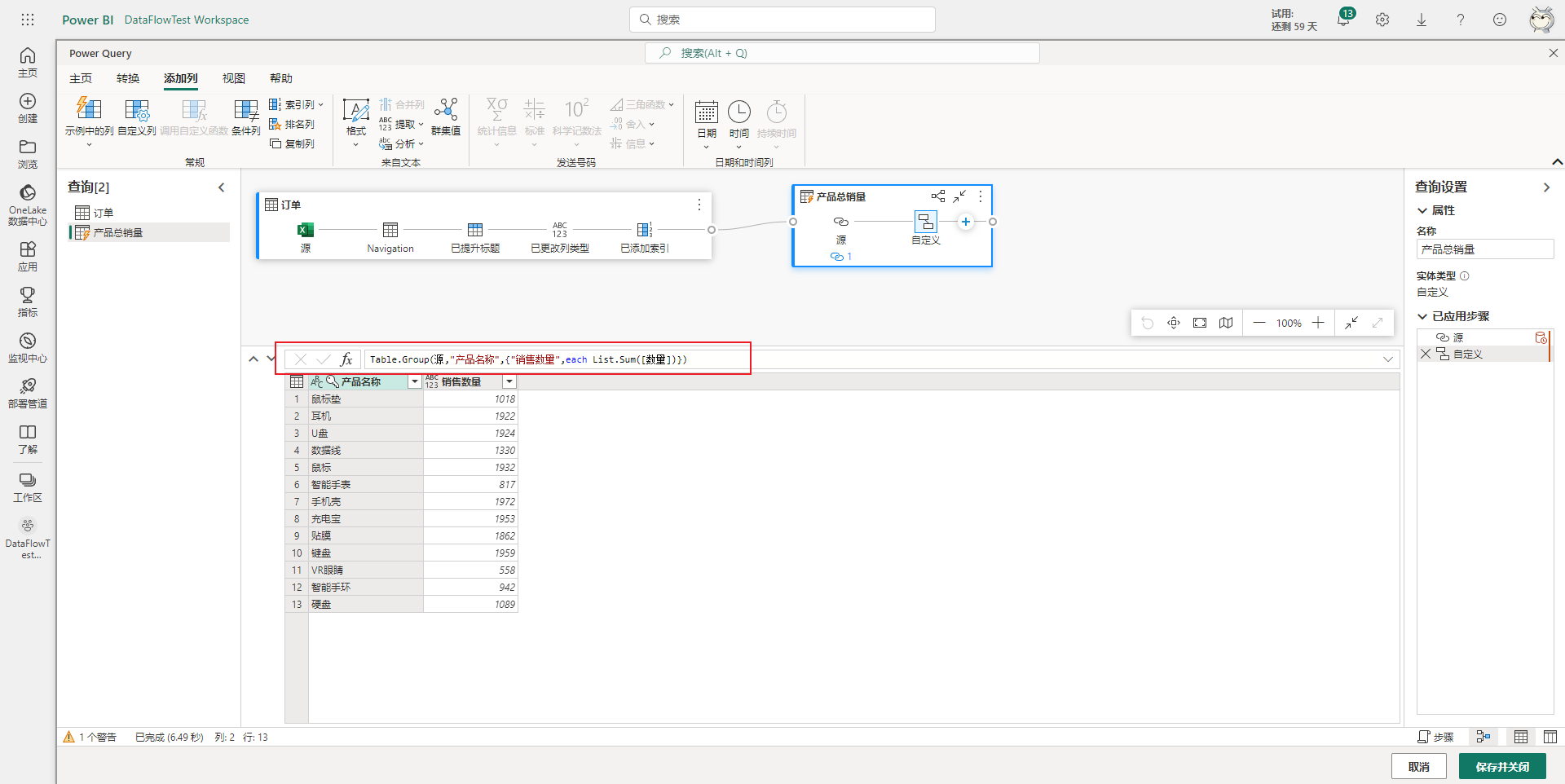
然后添加清洗步骤进行分组聚合,以统计各产品的销量,可以通过界面化操作或M语言来完成。这里选择使用M语言来实现,最后相应的修改新查询的名称为产品总销量。如下图所示。
假设到这里已经完成了所有的数据处理,那么点击右下角的保存并关闭按钮即可,然后在跳转的页面里输入数据流的名称并保存,这里将数据流命名为:数据流A-订单表与产品总销量。
保存完毕后,点击右上角的关闭按钮,即可关闭数据流界面,返回到工作区界面。
最后,数据流初次创建与配置完成后,需要刷新一次,以从数据源中导入数据并存储,否则数据流上无数据。因此需要先手工刷新一次,在工作区界面里点击对应数据流的刷新按钮即可。
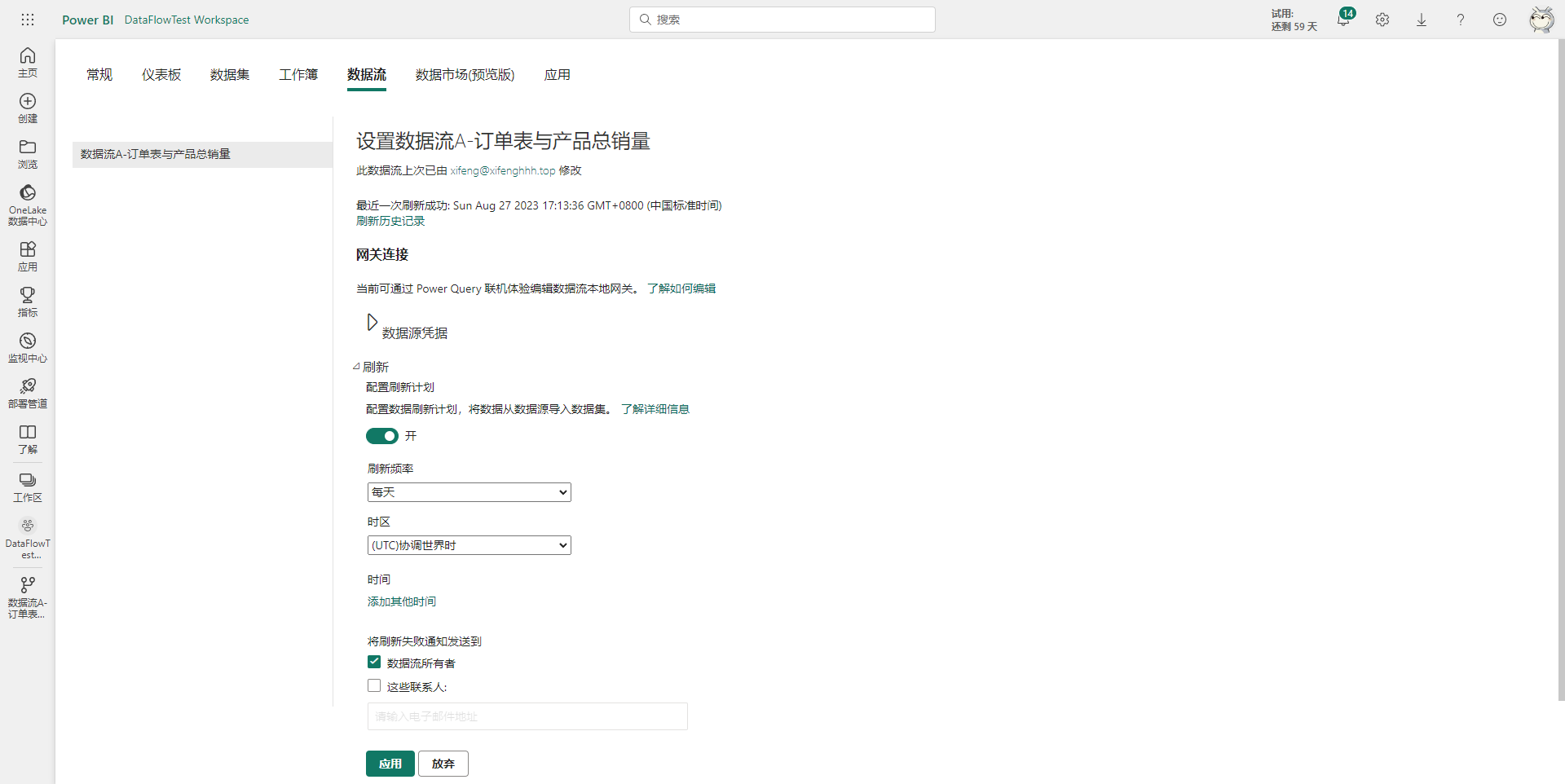
然后点击刷新按钮右边的三个点,进入数据流的设置页面,配置一下计划刷新,让数据流能按所需要的频率更新数据。
到这里为止,通过添加新表的方式创建数据流的整个过程已经介绍完毕。
2、添加链接表
假如现在新建的数据流想要使用上面已经创建好的数据流A的产品总销量表,那么就可以使用添加链接表功能,从而可以直接使用已经处理好的数据,而不再需要重新创建对应的表或查询,这也是一种提高数据重用性的做法。
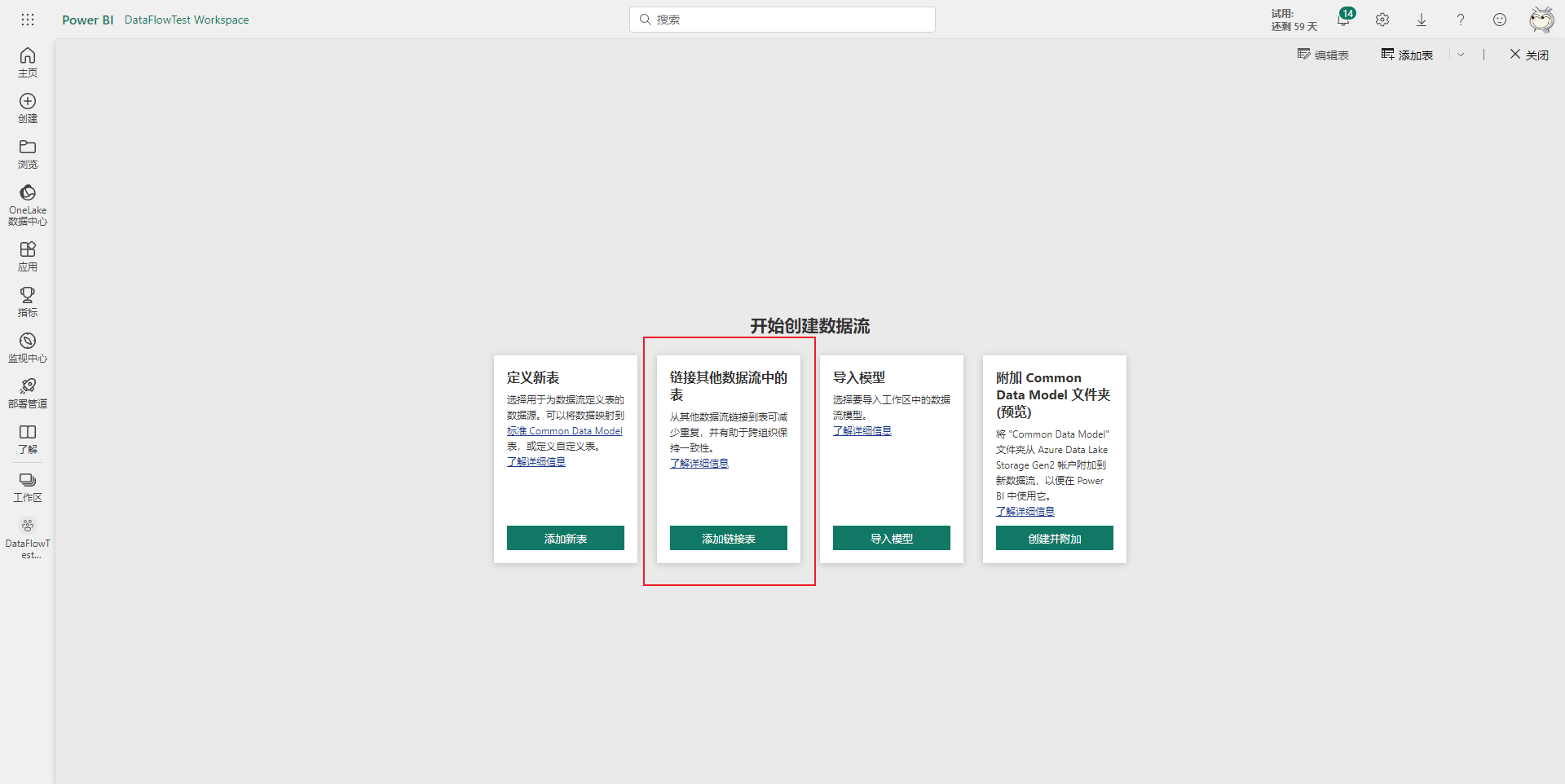
首先点击添加链接表按钮,然后在跳转页面里登录一下PowerBI账号,然后选择下一步。
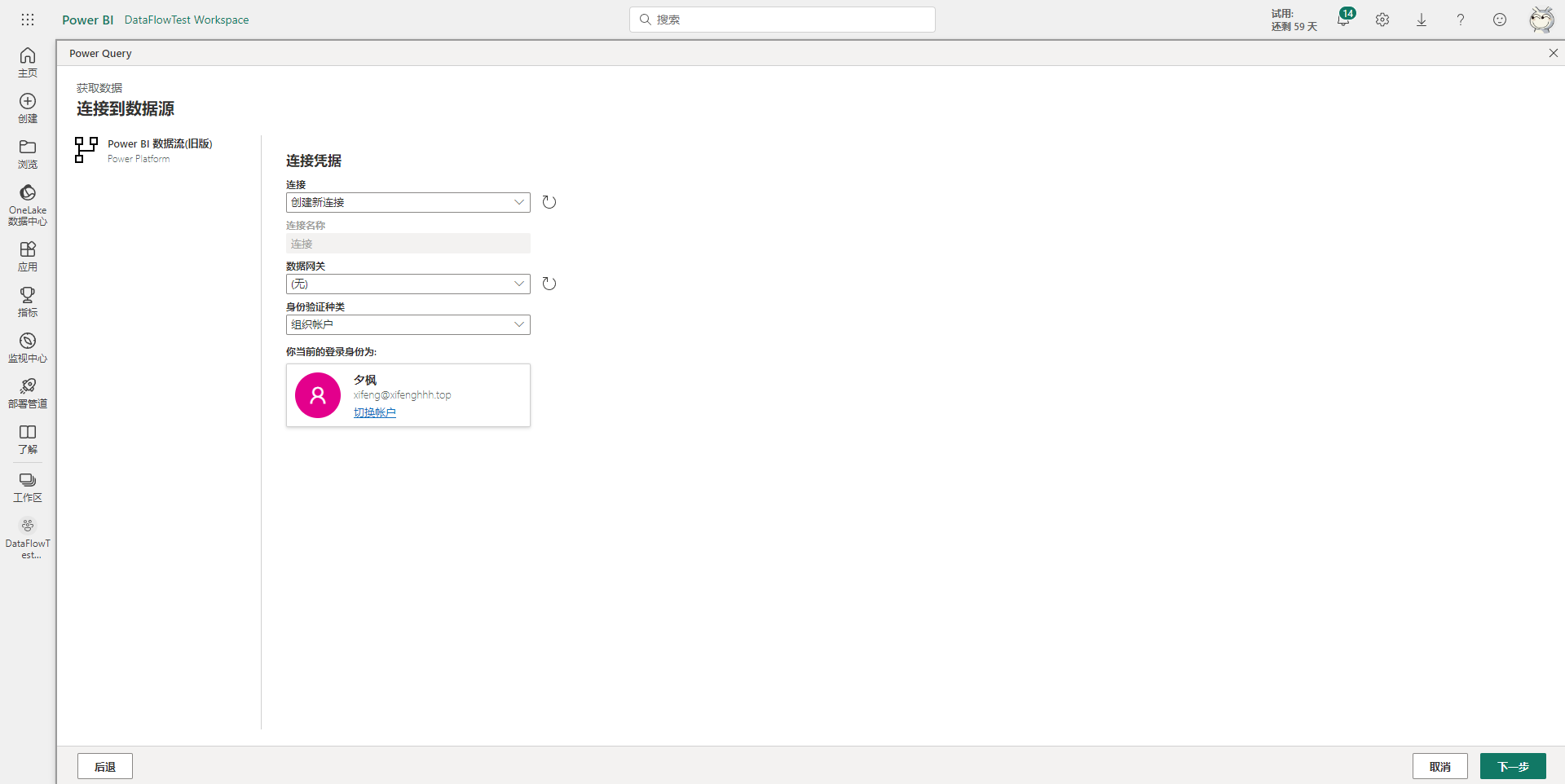
然后在跳转页面里可以看到所有工作区的数据流,选择需要使用到的其它数据流中的表,比如这里选择之前创建好的数据流A中的产品总销量表,然后点击右下角的转换数据,进入到PowerQuery编辑器。
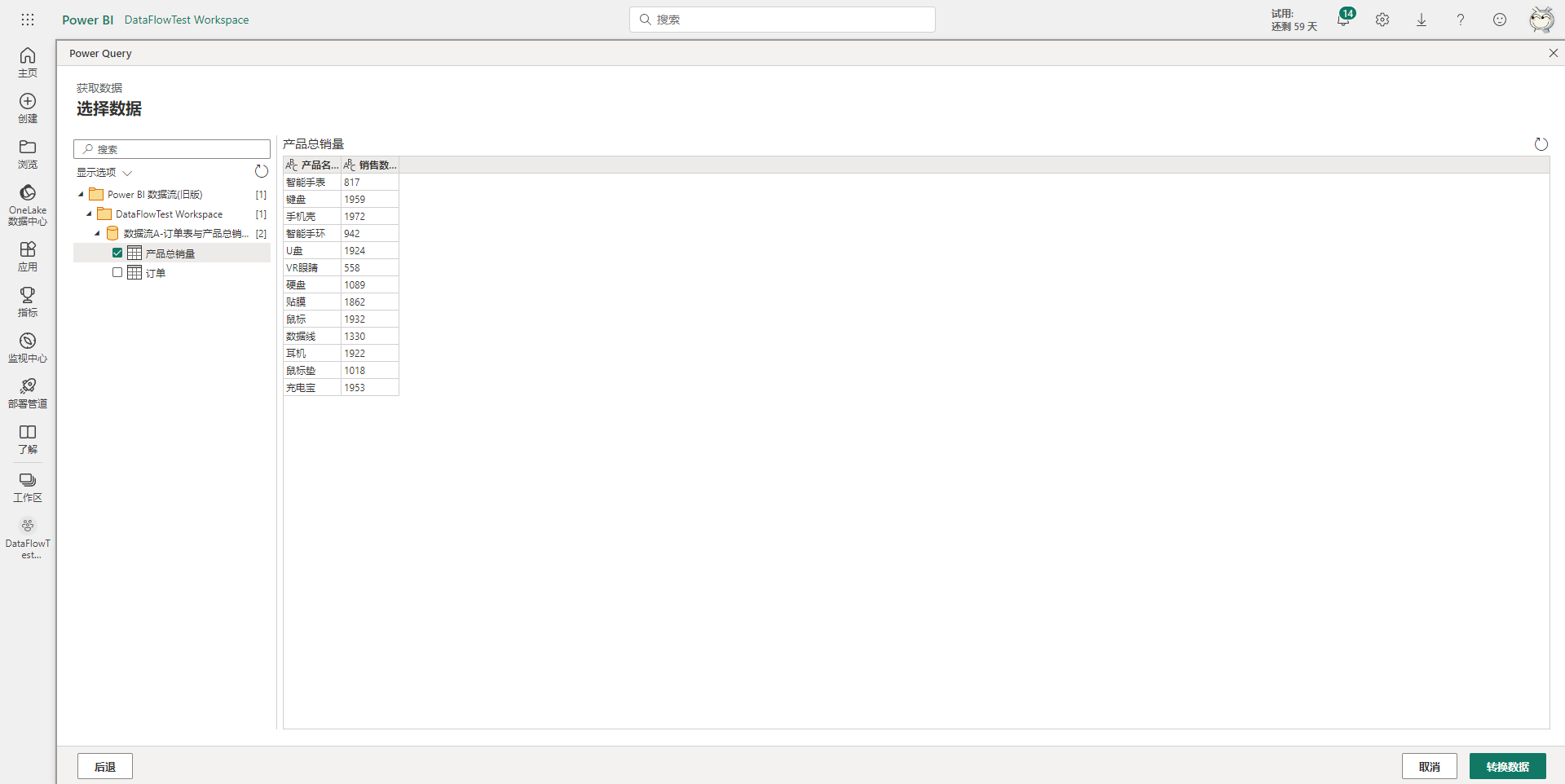
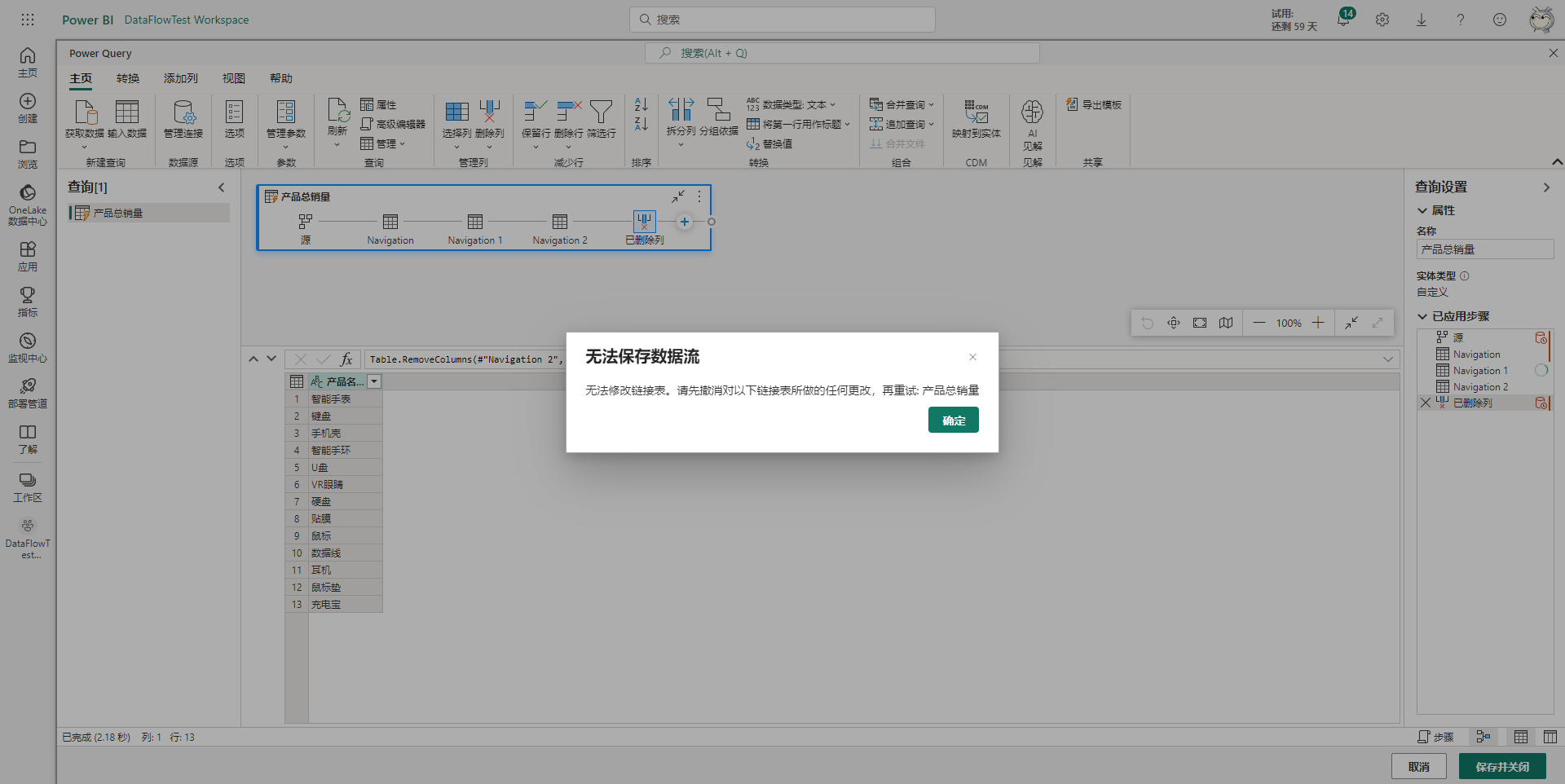
进入PowerQuery编辑器后,就可以看到刚刚添加的其它数据流中的表,这些其它数据流中的表称为链接表。链接表比较特殊,不能进行任何更改,比如添加新的清洗步骤等。当选中链接表时,可以在编辑栏下方看到一行提示:“无法修改链接表。对查询所做的任何更改都不会得到保存”,如下图所示。
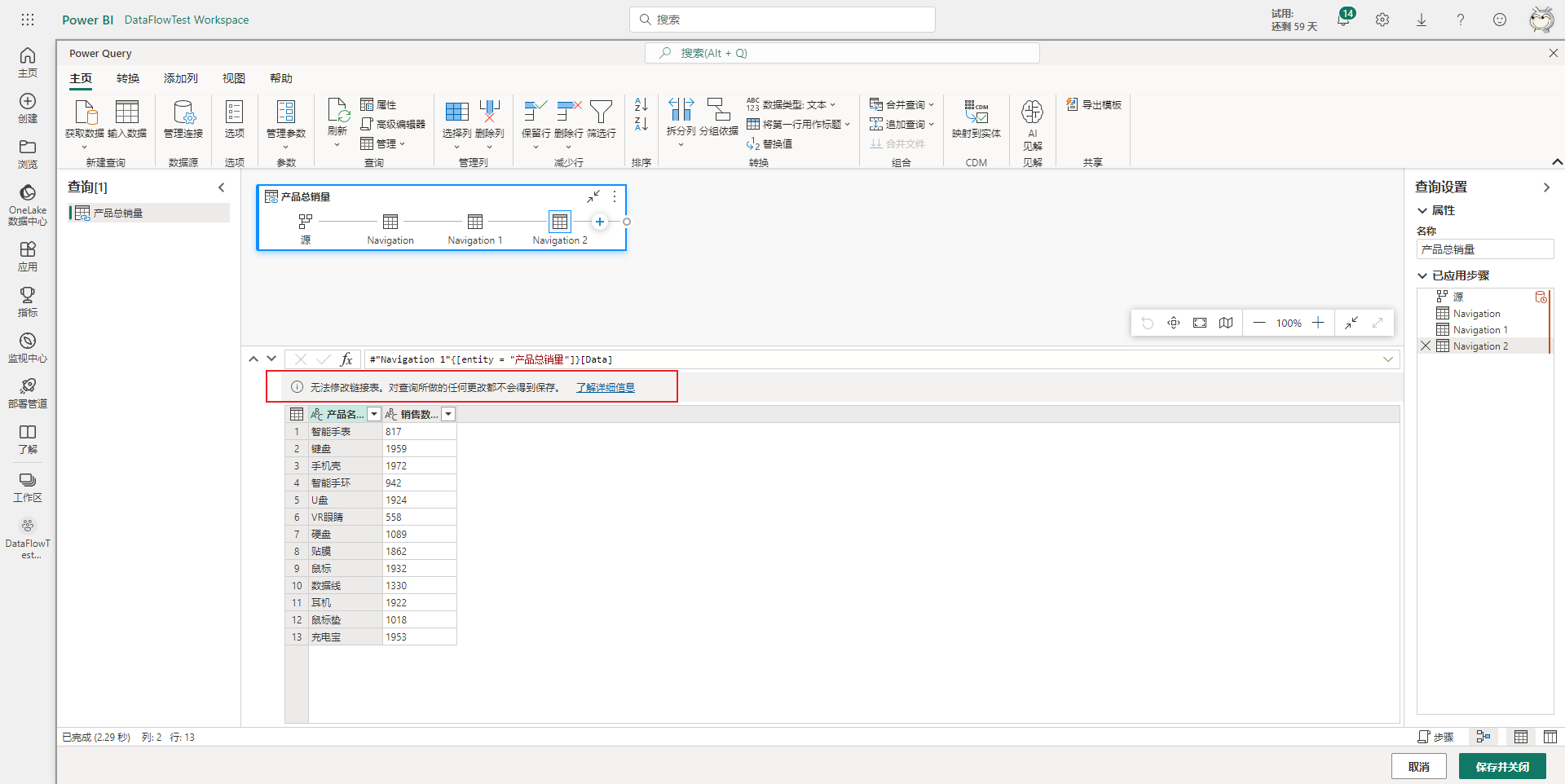
如果对链接表进行了更改,更改时不会报错,但当保存数据流时则会出现报错提示,需要撤销对链接表所做的所有修改后才能保存,如下图所示。
因此,如果想要使用链接表的数据进行二次计算,那么只能是创建新的查询,然后在新的查询上使用链接表的数据或对链接表进行修改。
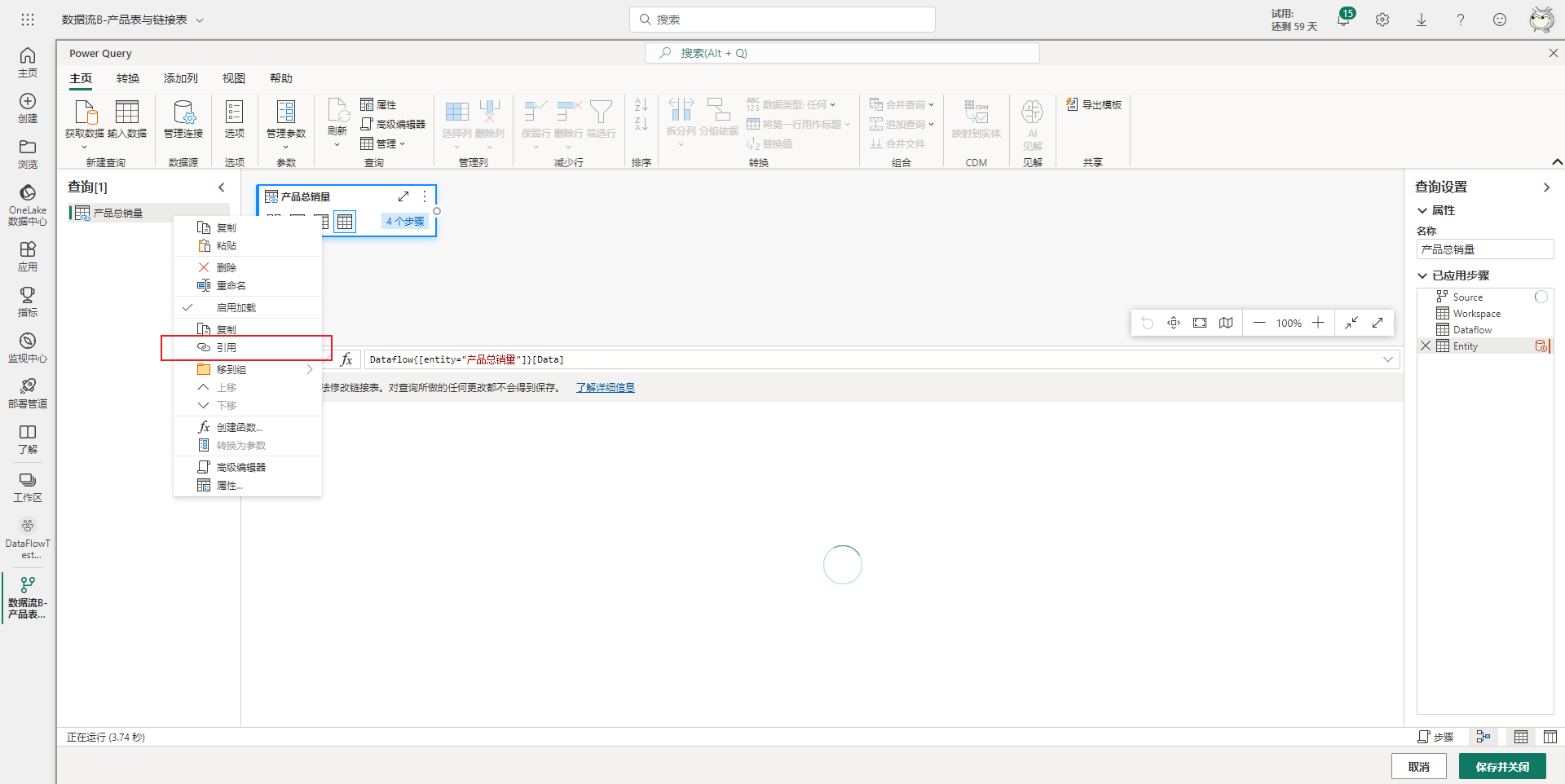
比如想对上面添加的链接表添加一个索引列,那么可以这样操作。首先引用链接表生成新的查询,如下图所示。
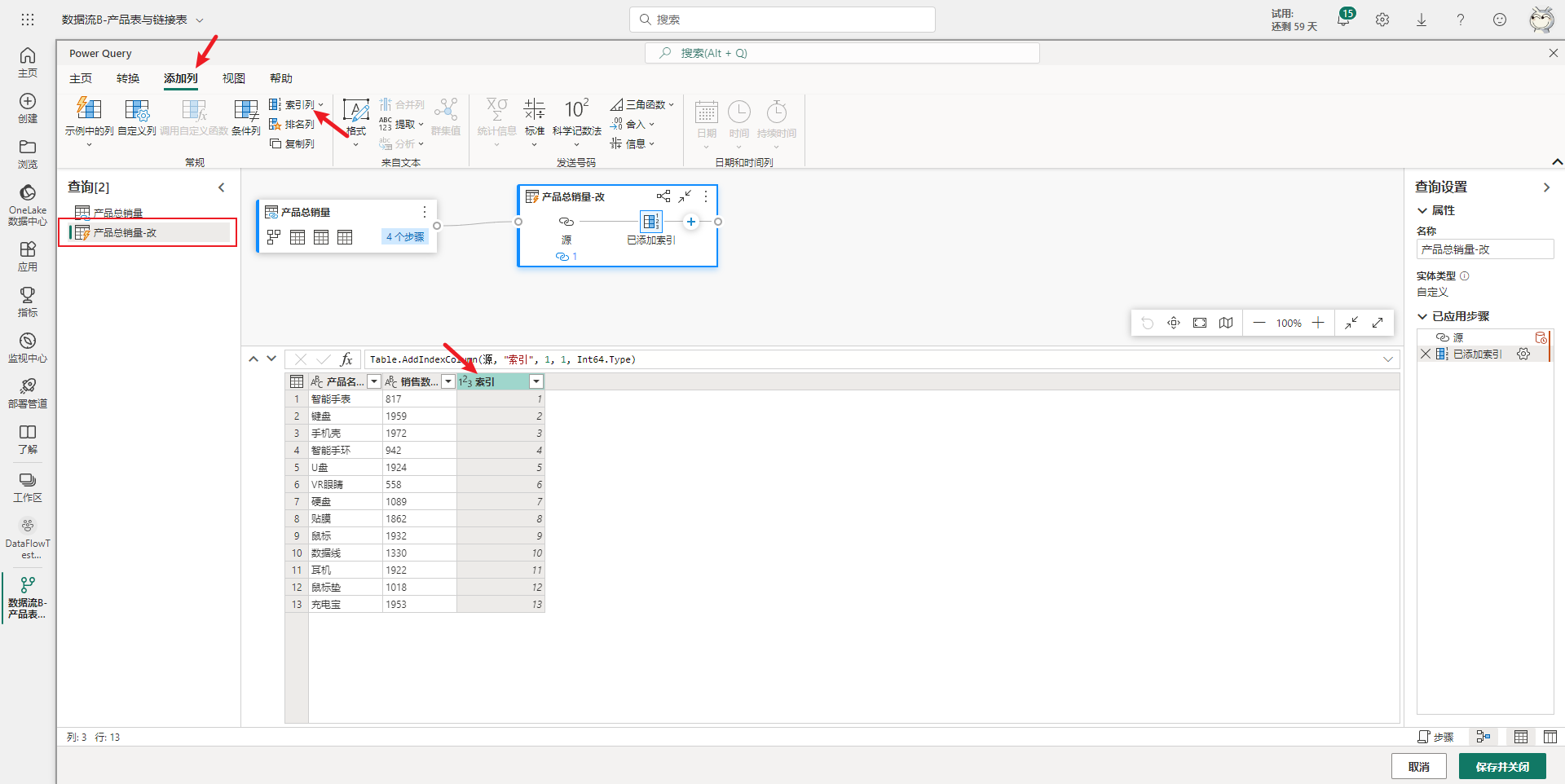
然后在新生成的查询上添加索引列,并修改表名为:产品总销量-改,如下图所示。
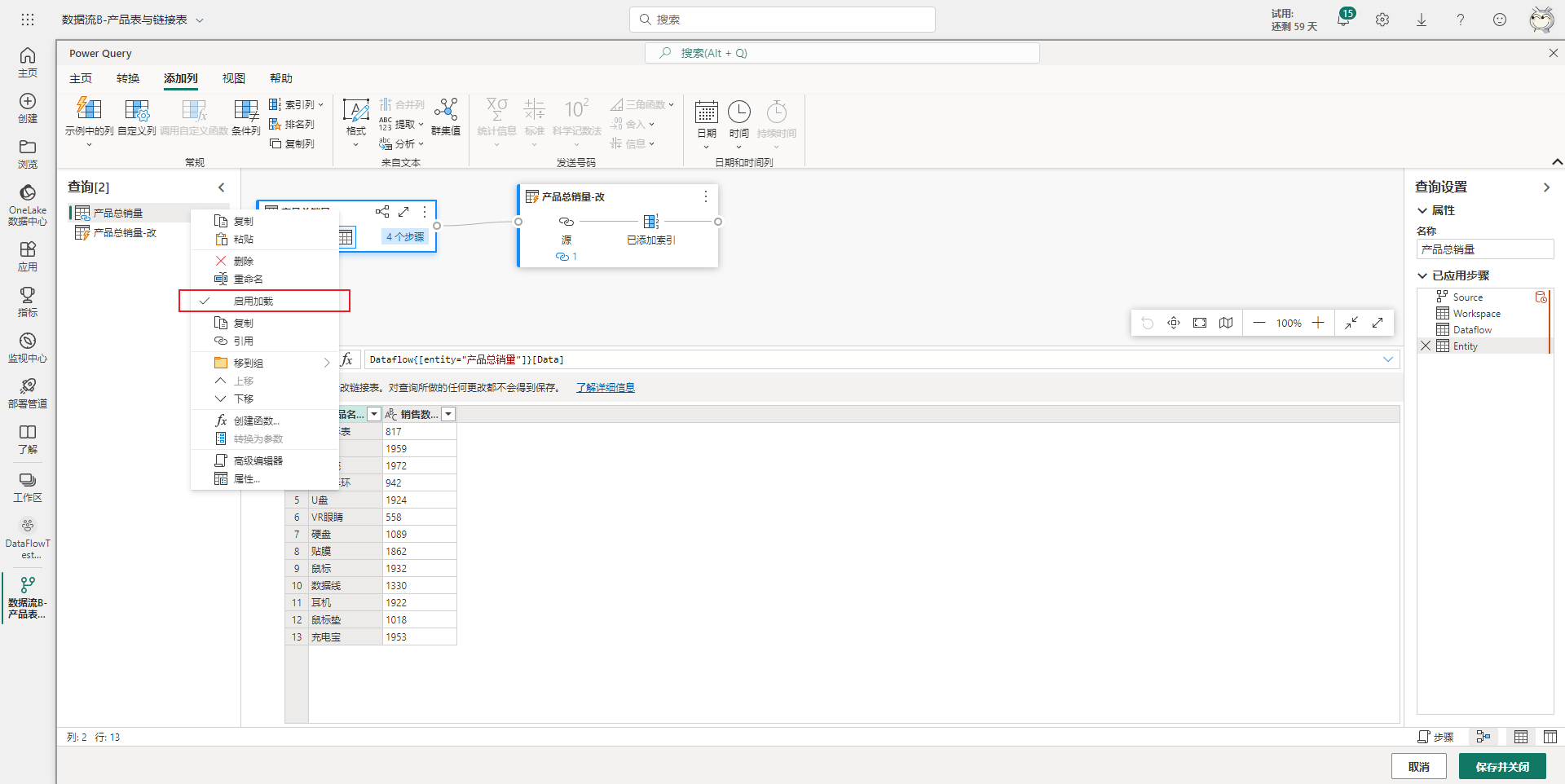
此时的链接表显得有点多余,那么可以考虑将链接表的启用加载选项去掉勾选,禁用链接表的加载,只加载新查询,如下图所示。这里为了方便后续的介绍,因此就不禁用链接表的加载。
接下来继续从Excel文件中添加要用到的另一张表:产品表。在主页选项卡最左边找到获取数据按钮,并选择Excel工作簿,如下图所示。
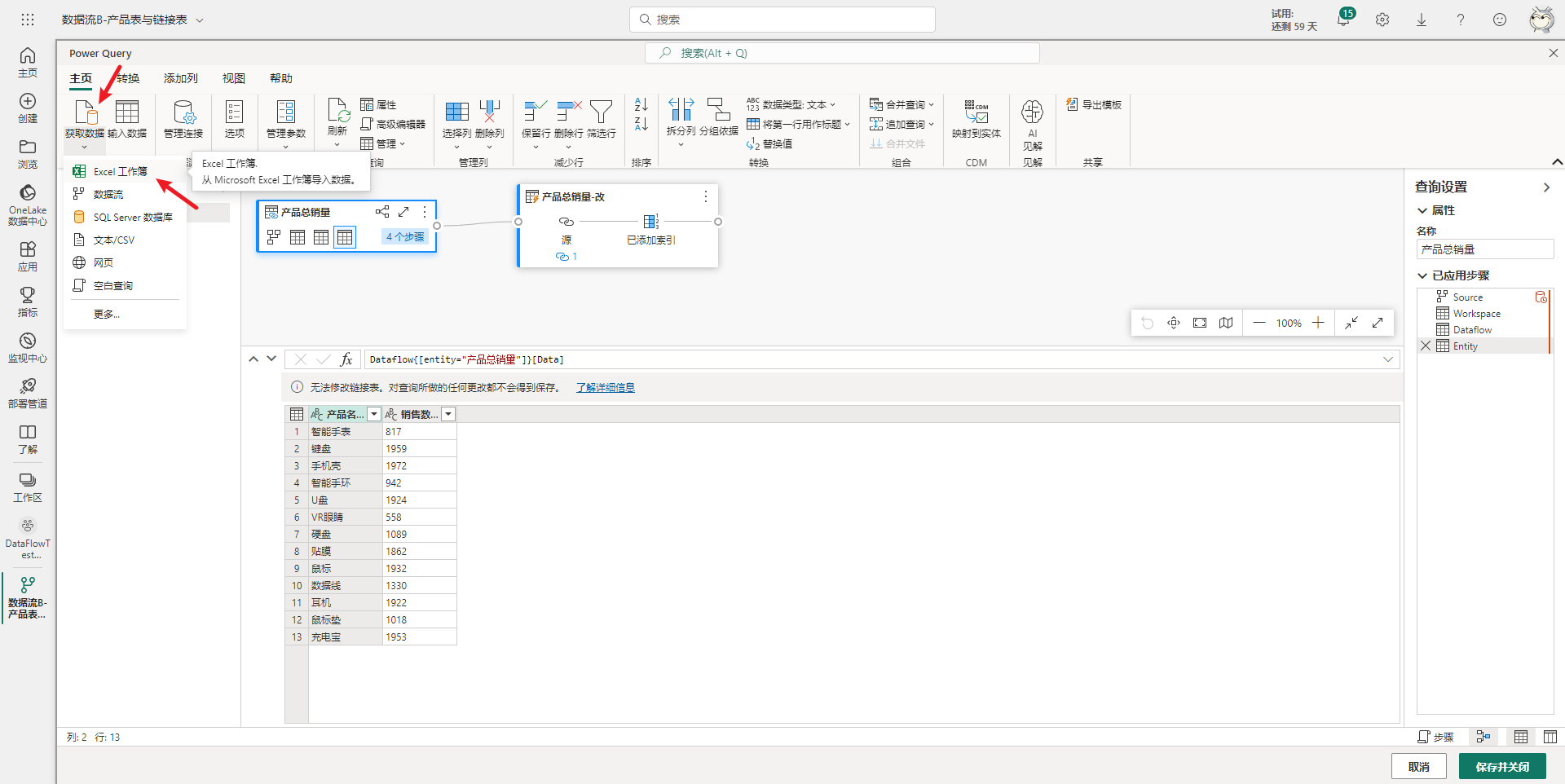
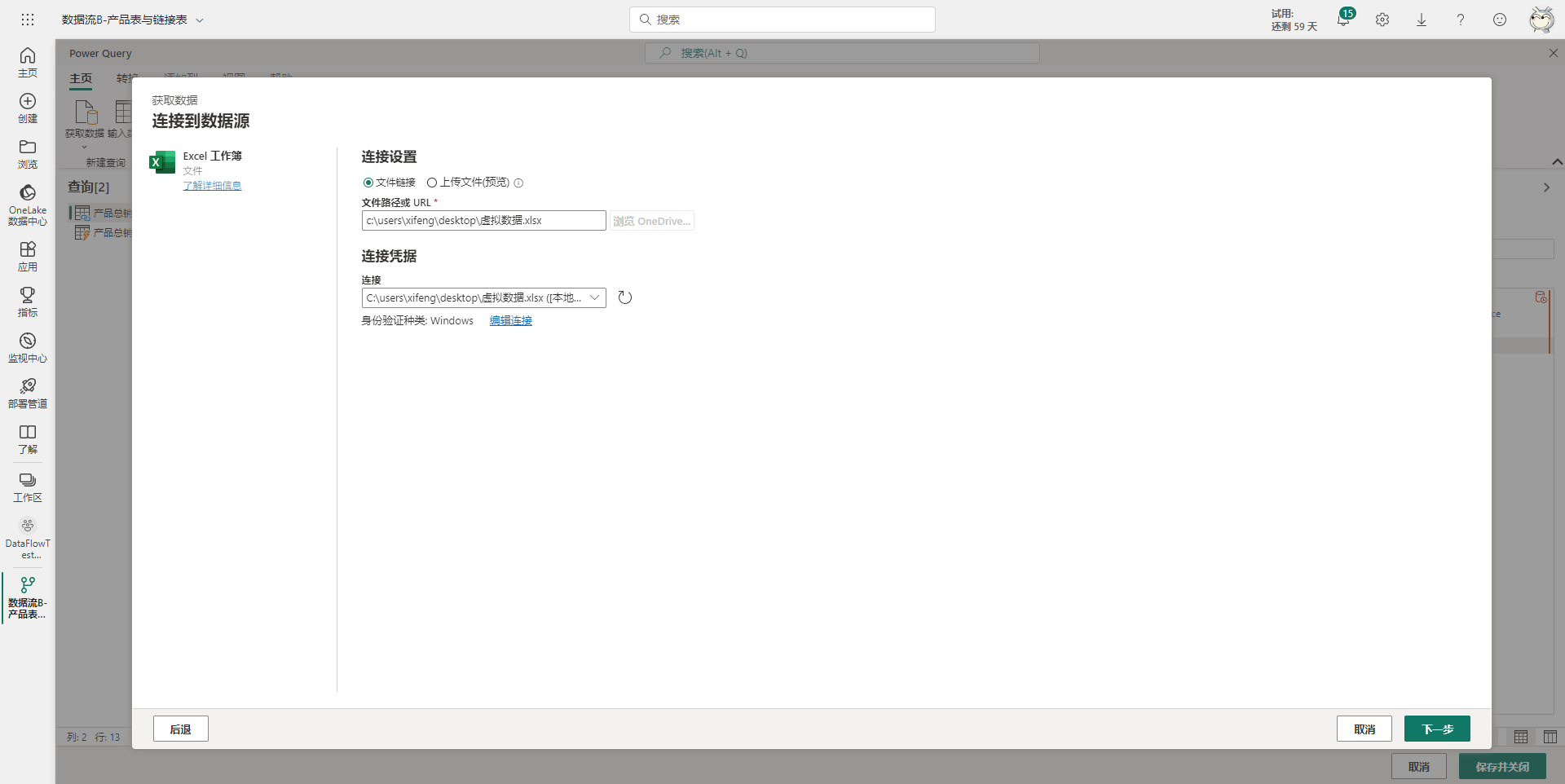
然后输入Excel文件的文件路径,以及配置连接凭据。
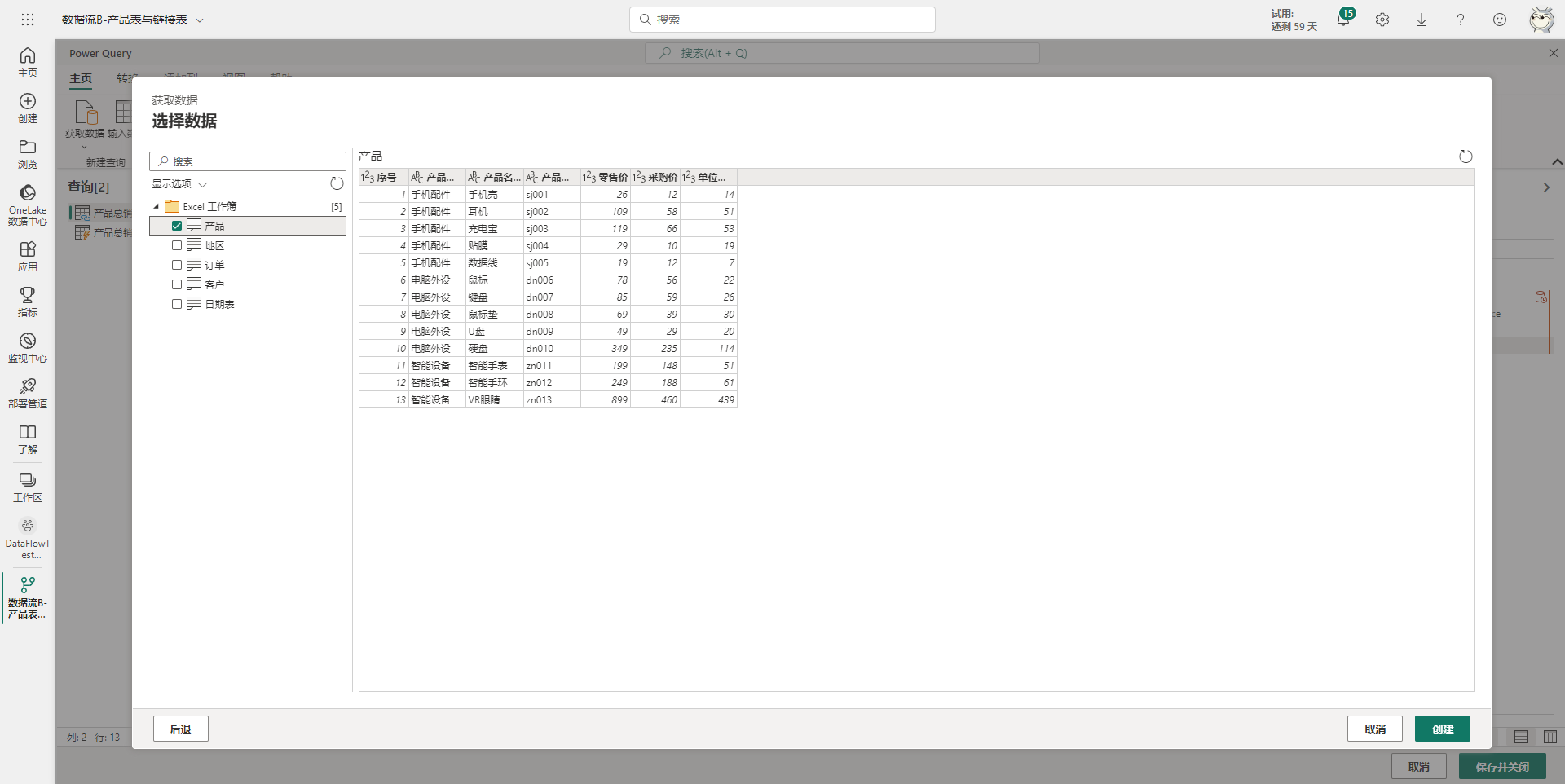
然后选择产品表,并点击右下角的创建按钮,即可将产品表添加进数据流中。
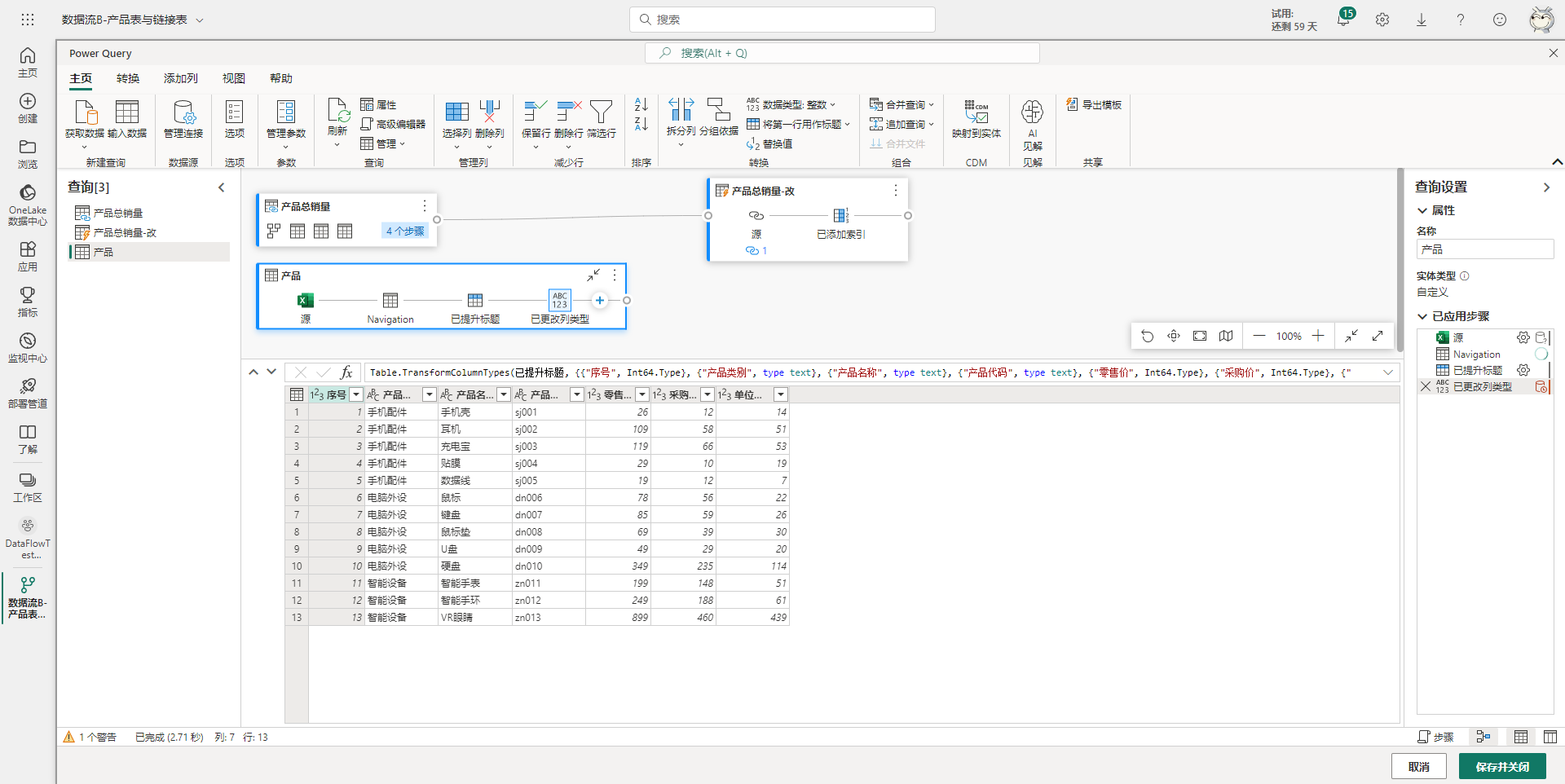
假设到这里已经完成了所有的数据处理,点击右下角的保存并关闭按钮进行保存,然后在跳转的页面里输入数据流的名称并保存,这里将数据流命名为:数据流B-产品表与链接表。最后还需要手动刷新一次数据流B,以及配置计划刷新。
那么到这里,添加链接表的整个过程也介绍完了,唯一需要注意的就是不要直接修改添加进来的链接表即可,其它地方基本都一致。
3、导出与导入数据流
当需要将数据流移动到其它工作区,或者只是想保存下来做个备份,此时就可以利用导出功能,将数据流的定义文件导出到本地。具体操作也很简单,只需要在工作区界面中选中需要导出的数据流,在右边三个点里找到导出json选项,然后在本地找个位置存放即可,具体如下图所示。
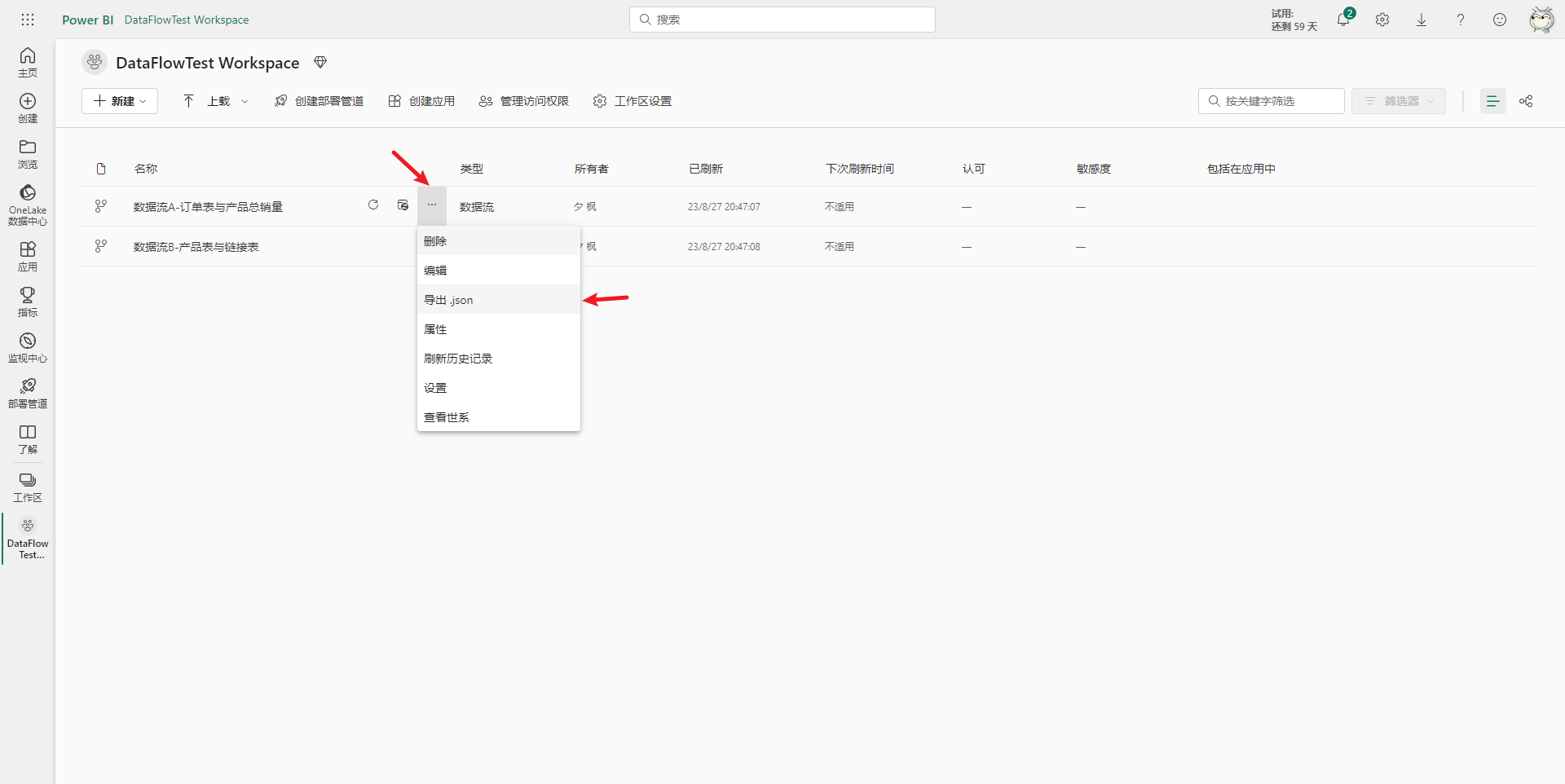
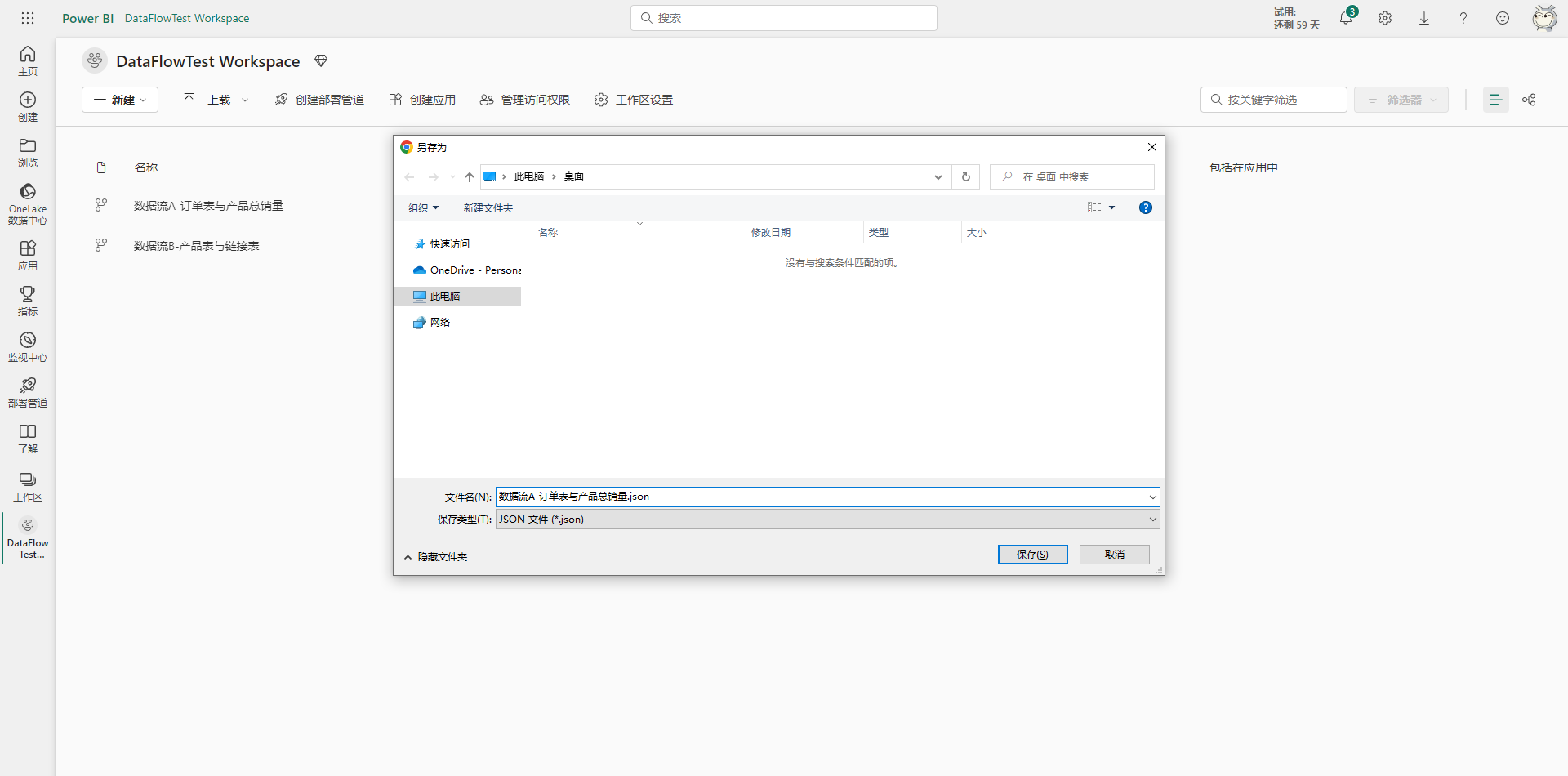
然后转到另一个工作区,假设之前导出的数据流现在要迁移到这个工作区中,在新的工作区里选择新建数据流。
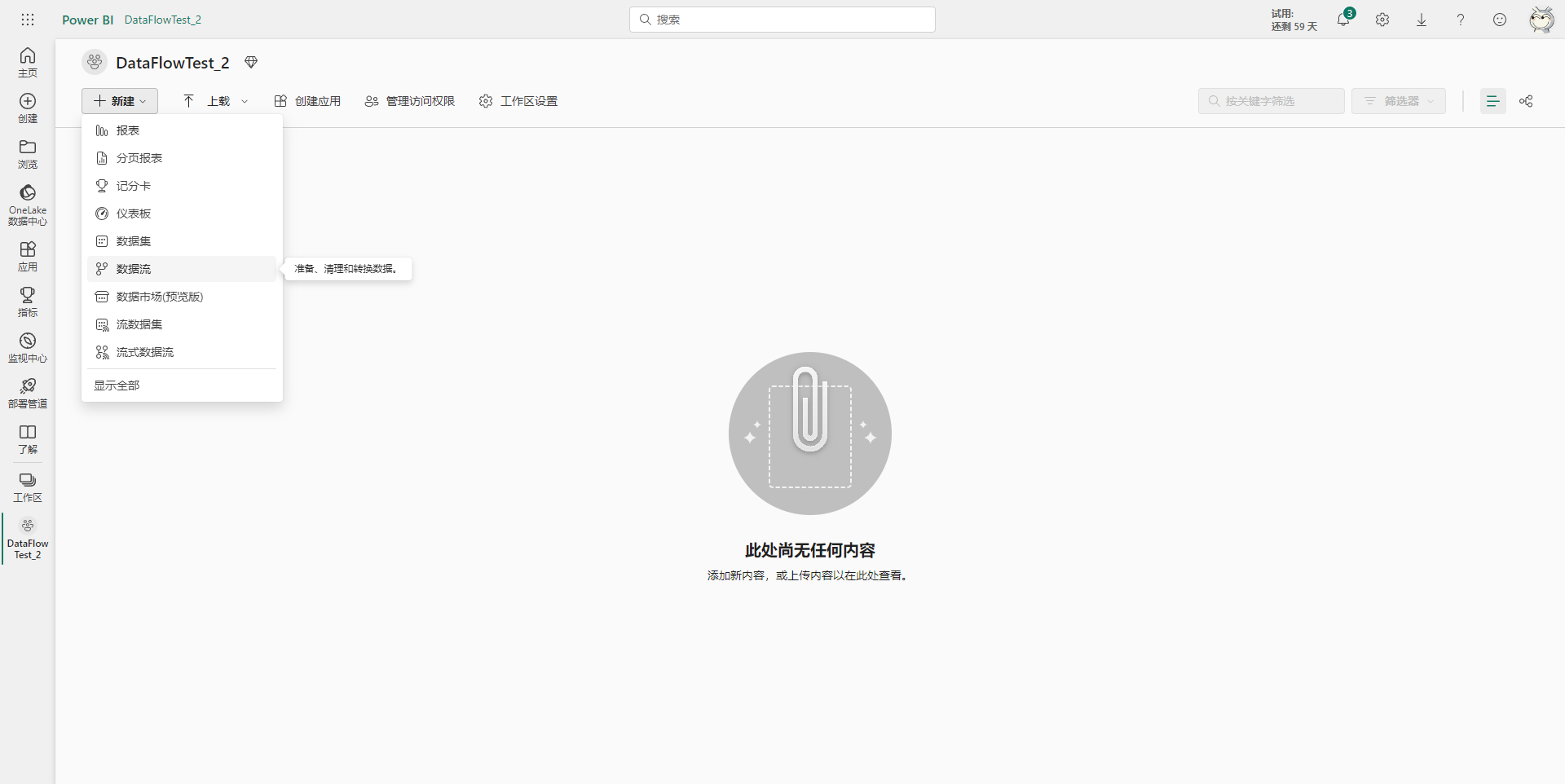
然后选择导入模型选项。
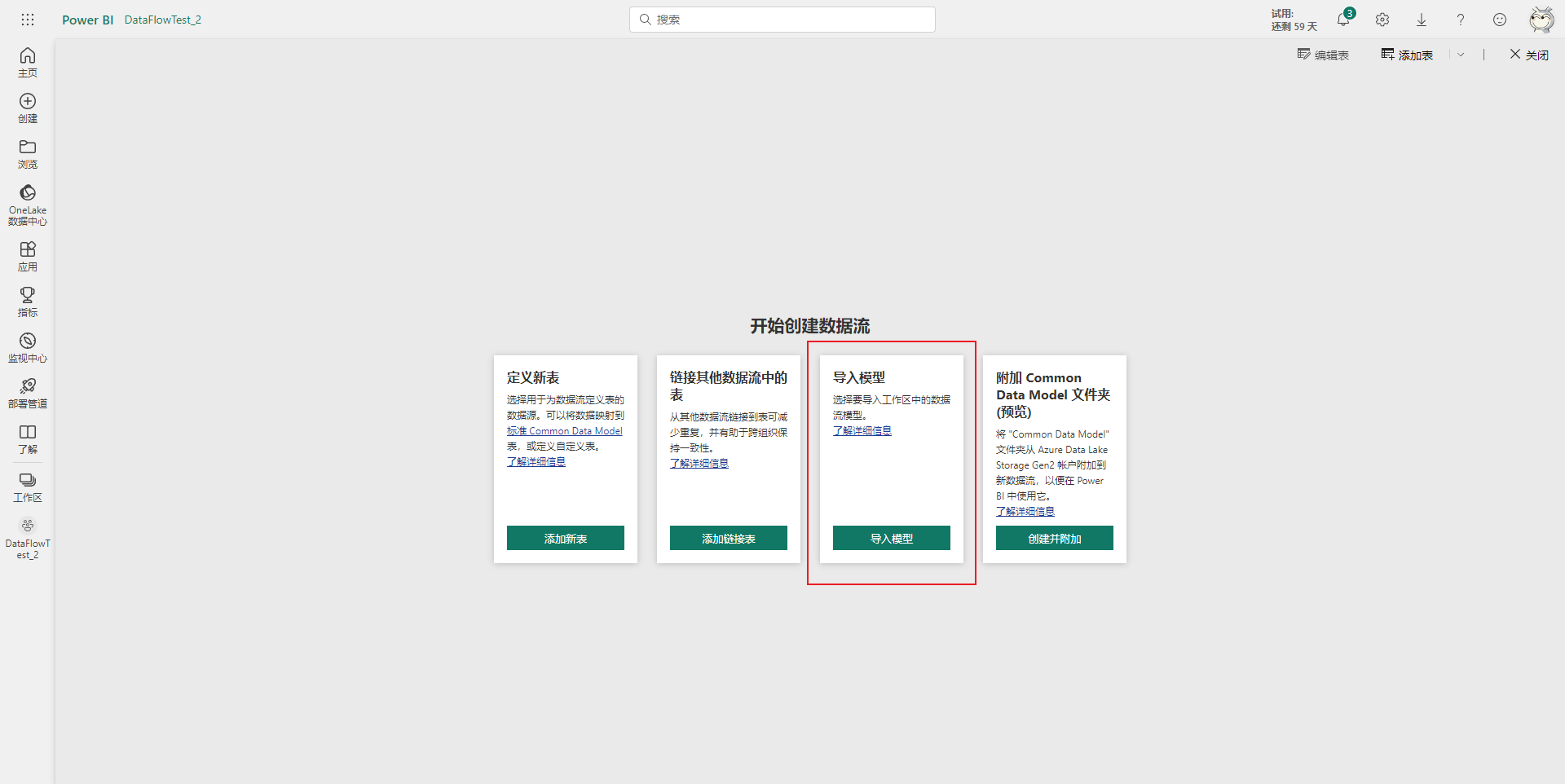
在浏览窗格里选中之前导出的数据流json文件,并打开。
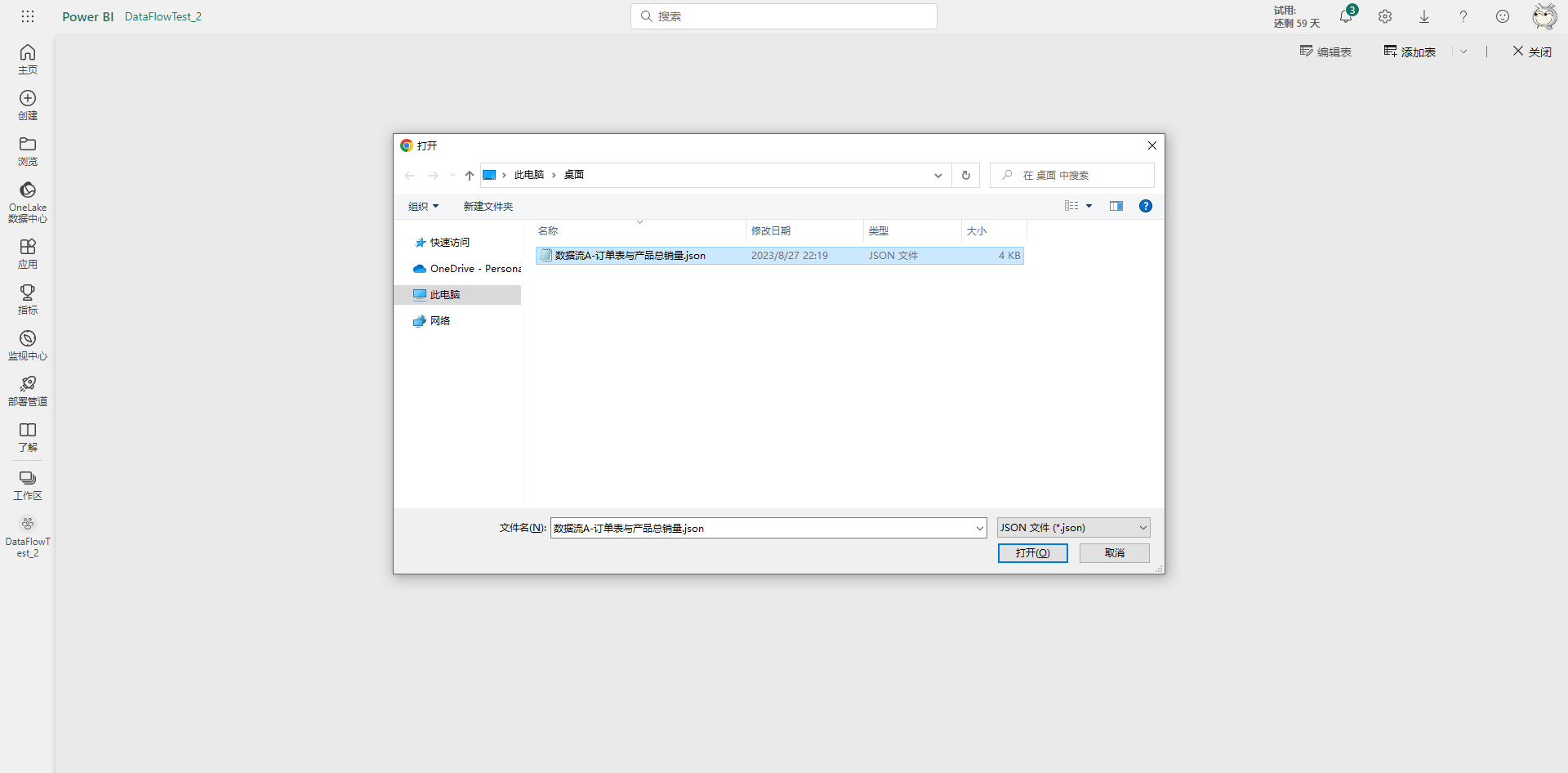
然后稍微等待一会,即可看到成功创建数据流的提示。

然后回到工作区界面,即可看到迁移过来的数据流,然后手动进行一次刷新与配置计划刷新即可。
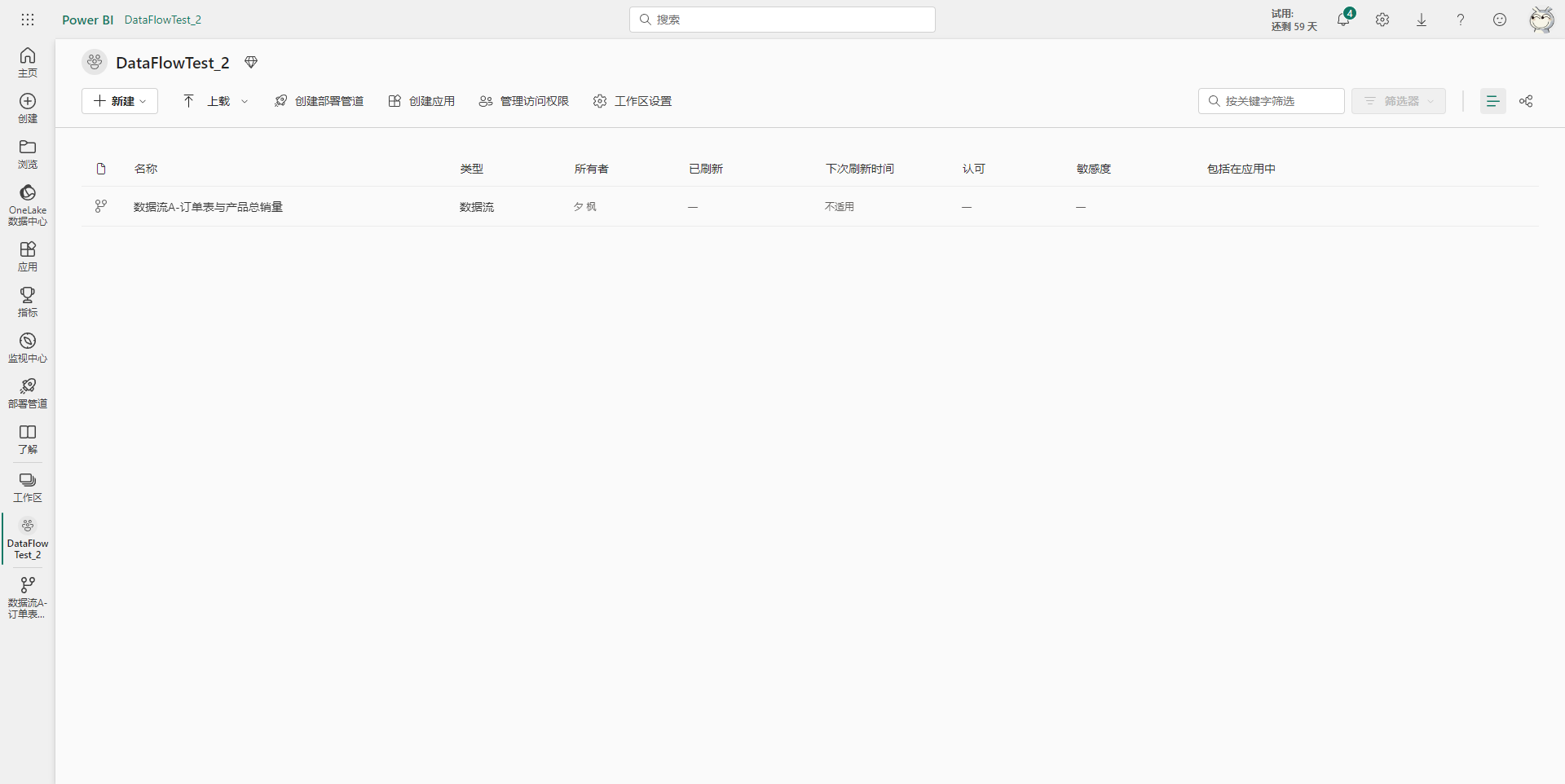
此时,该数据流存在于两个工作区中,再将旧工作区的该数据流删除,即可完成迁移。
数据流的高级功能与注意事项
前面介绍了数据流的基本用法,整个过程看起很流畅,没遇到什么阻碍,但这其中其实隐藏了一些细节。比如计算表与链接表其实是数据流的高级功能,需要在高级容量工作区(Premium)中才能使用的,在共享容量工作区(Pro)中则会报错。将上面使用到的工作区降级为共享容量工作区后,之前定义的数据流将被禁用,而且打开数据流后还会看到警告提示,如下图所示。
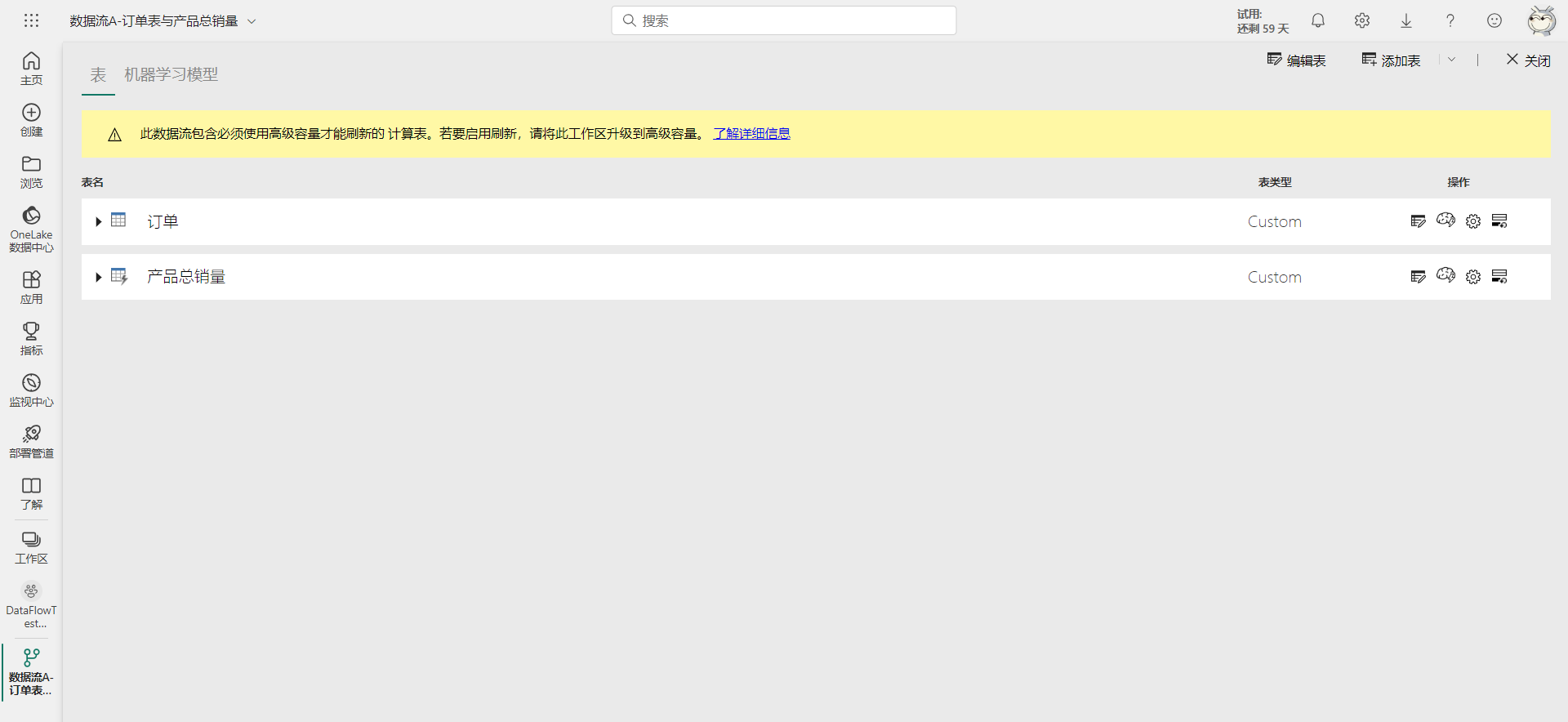
因此,为了更好的掌握数据流的使用,还需要掌握数据流的一些概念,以及一些注意事项等。
源表:对某个启用加载的查询来说,如果其不是链接表且其位于引用世系的起点或其前面的所有父级查询均未启用加载,那么该查询即为源表,源表的标志为一个表格,右下角无任何标志。源表是从数据源中获取数据的查询,是后续所有计算的开始。
计算表:对某个启用加载的查询来说,在引用世系中,如果其前面的任意父级查询有启用加载,那么该查询即为计算表,计算表的符号在右下角有一个黄色雷电标志。使用计算表可以在同一个数据流内引用已有查询的数据,而不再需要重新向数据源发送获取数据的请求,可以提高数据的重用性。
链接表:引用其它数据流中的表时会在当前数据流中创建该引用表的数据副本,称为链接表,链接表的符号在右下角有一个蓝色超链接的标志。使用链接表可以引用其它数据流中已有的数据,而不再需要重新向数据源发送获取数据的请求,可以提高数据的重用性。
增量刷新:可以对数据流中的某些表设置增量刷新,以避免每次刷新时都请求所有数据,可以降低数据源的服务器负载。
增强的计算引擎:启用了增强的计算引擎后可以加速数据流中的计算类操作,并使数据流支持Direct Query。
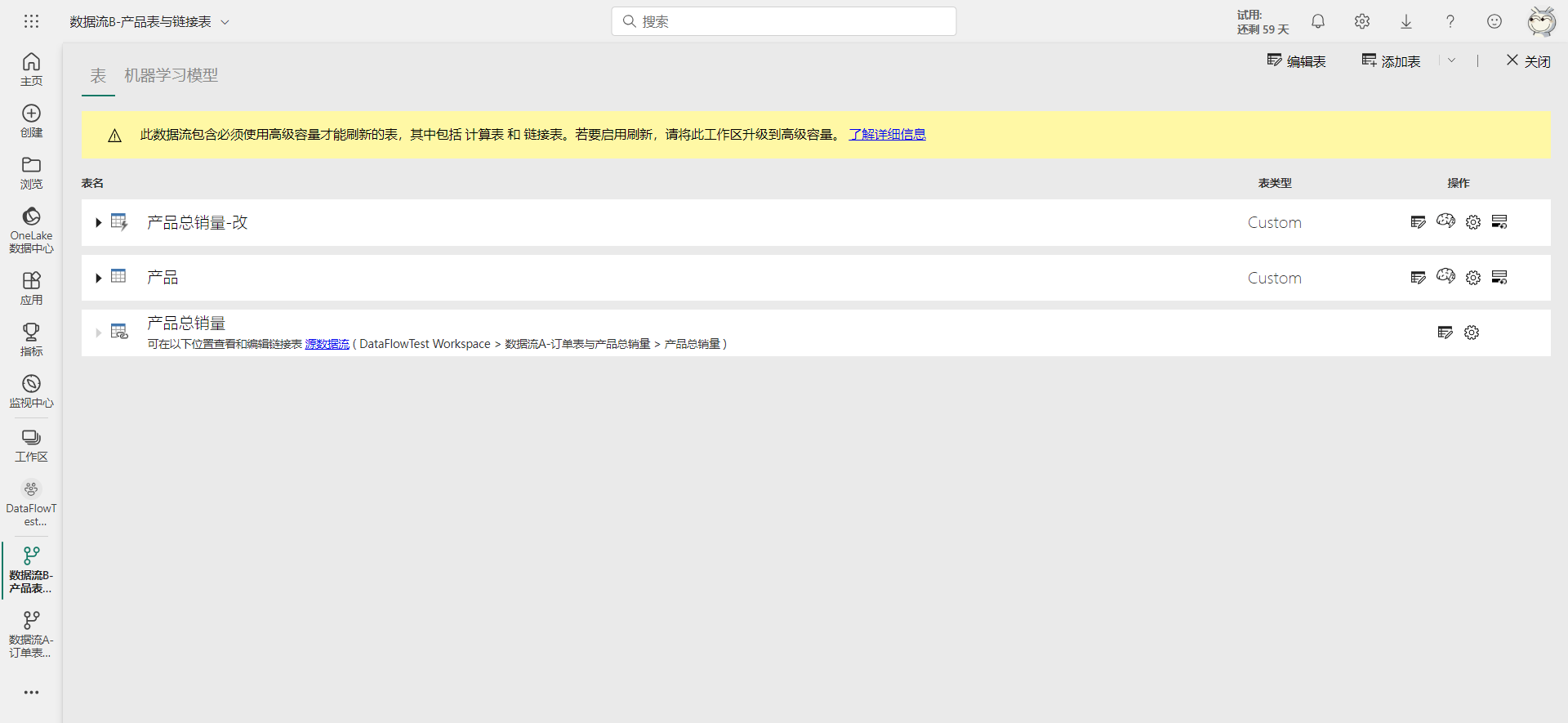
以之前创建的数据流B为例,根据上面的定义,数据流B中的三个表的类型如下图所示。
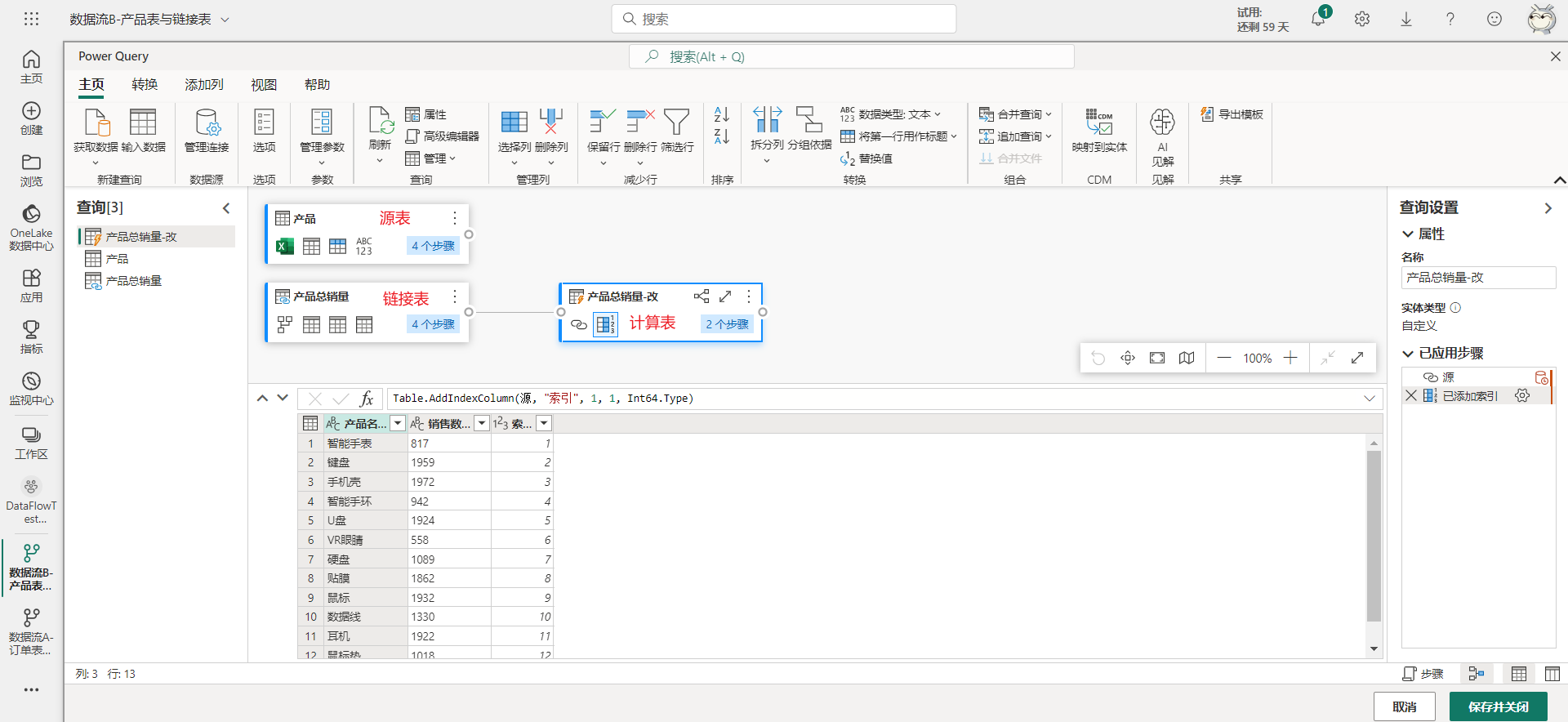
链接表应该是比较好理解的,只要是来自其它数据流的表都是链接表。但源表与计算表会随着引用世系以及父级查询是否启用加载的变化而变化。比如将数据流B的链接表禁用加载,那原本该链接表的计算表会变成源表,如下图所示。
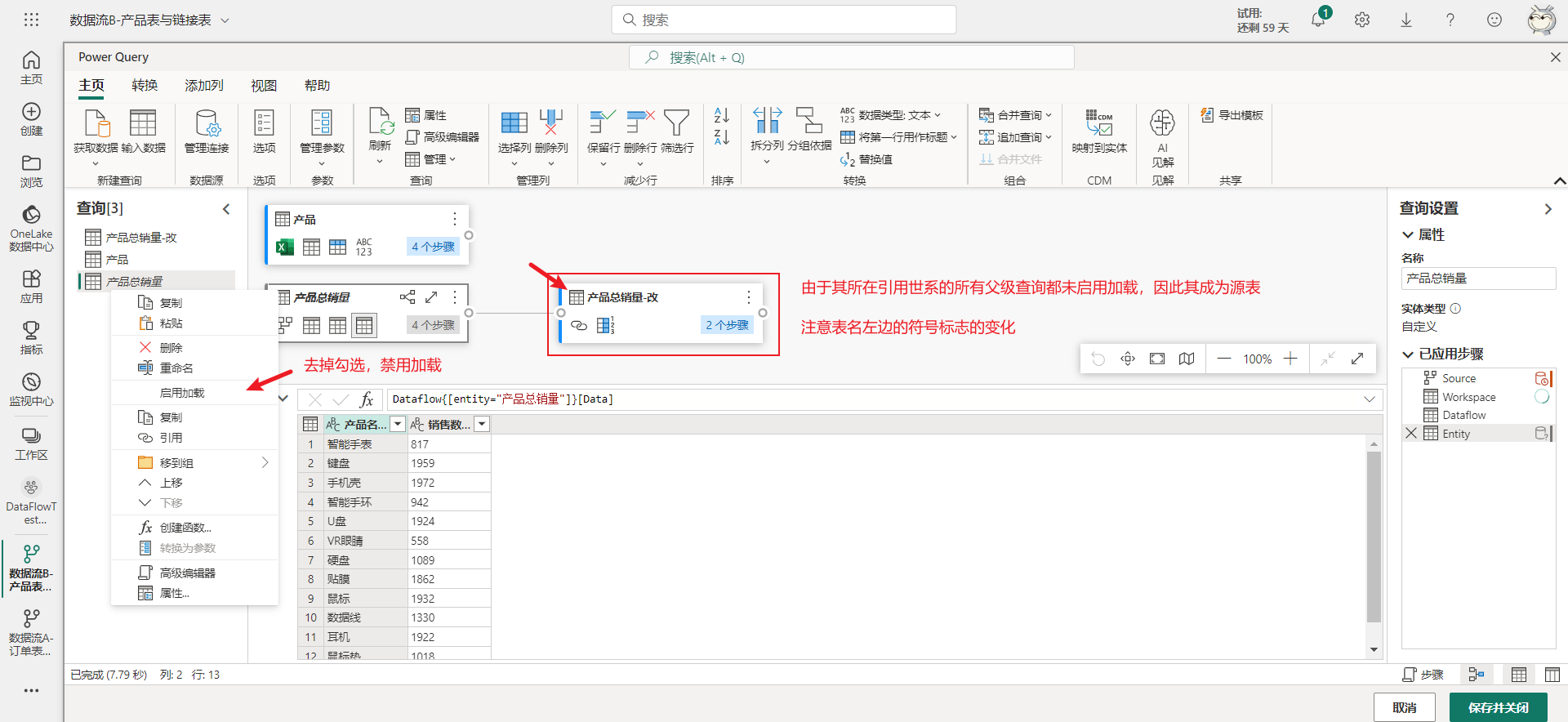
经过上面的修改后,链接表被禁用加载,而之前该链接表的计算表变成了源表,那么在数据流B中就只有源表了,不存在需要在高级容量工作区中才能使用的计算表与链接表,因此现在数据流B可以在共享容量工作区中使用。
下面来看一些注意事项:
1、计算表、链接表、增量刷新、增强的计算引擎、Direct Query等功能都是数据流的高级功能,需要在高级容量工作区中才能使用。
2、需要打开增强的计算引擎后才支持Direct Query,因为Direct Query下的计算会发送回数据源(这里指的是数据流)进行计算,因此必须启用了增强的计算引擎后才能支持Direct Query。
3、增强的计算引擎共有三个设置:已禁用、已优化、开,其中已优化的意思指的是当有计算表或链接表存在时会临时启用增强的计算引擎以增强性能,但这只发生于刷新时,刷新完成后就自动关闭了,因此选择已优化的选项将不支持Direct Query模式。
4、当切换增强的计算引擎功能的开关时,会清空数据流上的数据。
5、数据流初次创建与配置完成后,需要刷新一次,以从数据源中导入数据并存储,否则数据流上无数据。
6、当数据流上无数据时,即使启用了增强的计算引擎,PowerBI在进行连接时仍然只能使用导入模式,而不能使用Direct Query。
7、链接表的刷新只是与其所在的源数据流进行数据同步,而不是按照完整的引用链条的代码逻辑从头开始计算。
8、链接表可以存在于共享工作区的数据流中,但链接表不能启用加载。
9、在链接表的计算表的清洗步骤中不要添加从其它数据源获取数据的步骤,否则刷新时会报错,应该创建一个新的查询来获取数据,然后链接表的计算表中引用新的查询来使用新的数据源的数据。
10、数据流的链式刷新只能在同一个工作区中才能自动触发。
11、具有工作区参与者及以上权限时,可以接管工作区中的数据流,从而成为数据流的所有者。非数据流的所有者不能编辑数据流,即使是工作区的管理员也不行,必须先接管数据流成为数据流的所有者后才能编辑。
12、无法单独共享某个数据流的使用权限给用户,只能是通过共享工作区权限的方式来共享数据流的使用权限。当授予工作区参与者及以上权限时,用户可以自行接管数据流成为数据流所有者,从而改变数据流的定义,因此一般授予工作区查看器权限即可。
数据流的链式刷新规则
数据流中各查询的定义以及清洗步骤决定了数据的质量,但另一个核心元素则是数据流的刷新,刷新过程保证了数据的有效性与及时性。
对于某个数据流而言,可以在其设置页面里配置计划刷新,使数据流按所设置的时间与频率自动刷新数据。计划刷新的配置非常简单,但其实也隐含了非常复杂的刷新规则在其中,那就是链式刷新规则。
从前面的介绍中可以知道,某个数据流中可以引用其它数据流的表,即链接表功能,该功能可以有效提高数据的重用性。如果某个数据流中不存在任何链接表,那么该数据流的刷新是很简单的,只需要刷新它自身即可。但对于存在链接表的数据流而言,其刷新过程还涉及到其所引用的链接表所在的数据流。
数据流的链式刷新规则总结如下:
当某个数据流进行刷新时,除了刷新它自身的所有表外,还会检查是否有同一个工作区的其它数据流引用了它的任意表,这里只考虑启用加载的表,然后那些引用了它的表的数据流也会自动被触发刷新,但刷新的并不是所有表,而是只刷新链接表以及链接表的计算表,那些来自其它数据源的表并不会被刷新。然后被自动触发刷新的数据流也会重复这个流程,去触发刷新那些同一个工作区中引用了它的任意表的数据流,因此称为链式刷新。
需要注意的是,只有同一个工作区中的数据流才会触发链式刷新,并且被引用的链接表需要启用加载,如果链接表没有启用加载,那么这个数据流并不会被触发刷新。另外,链接表的刷新只是与其所在的源数据流进行数据同步,而不是按照完整的引用链条的代码逻辑从头开始计算,因此如果想彻底刷新某个包含链接表的数据流,除了需要刷新它自身,还要去刷新它引用的链接表所在的数据流。
为帮助理解,下面以前面创建的两个数据流来讲解一下刷新的过程。首先,先回顾一下前面创建的两个数据流包含的内容。
数据流A,共有两个表,一个源表:订单,以及一个计算表:产品总销量,引用世系如下图:

数据流B,共有三个表,一个源表:产品,一个来自数据流A的链接表:产品总销量,以及一个链接表的计算表:产品总销量-改,引用世系如下图:
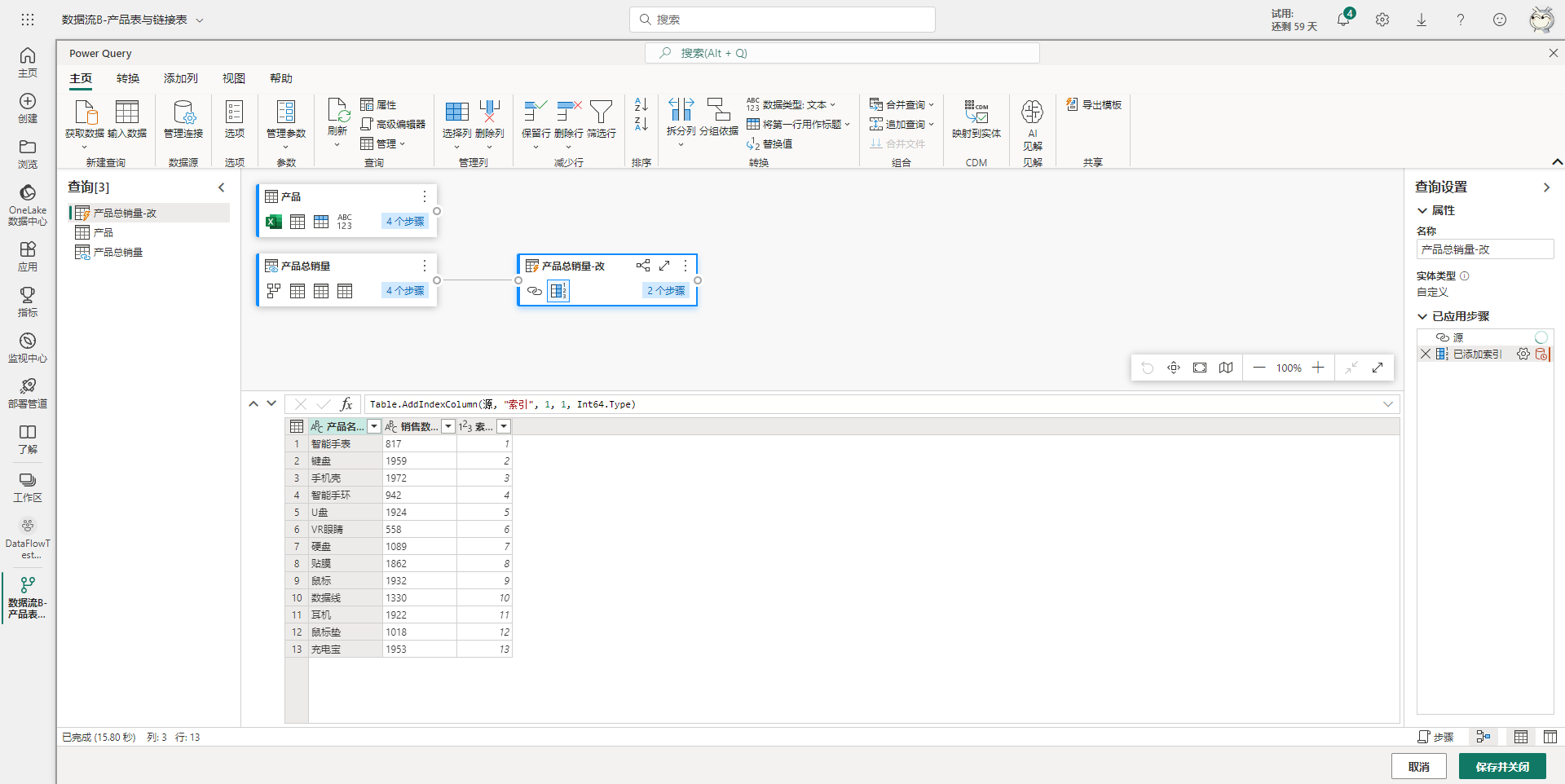
以上两个数据流处于同一个工作区中。
刷新场景:
- 数据流A刷新,且两个数据流的所有表都启用加载。首先刷新数据流A的所有表,然后检测到位于同一个工作区的数据流B引用了数据流A的产品总销量表,并且该链接表还启用了加载,因此自动触发数据流B的刷新。然后在数据流B中,只刷新来自数据流A的链接表与链接表的计算表,即只刷新数据流B中的“产品总销量”与“产品总销量-改”这两个表,数据流B中的产品表由于来自另一个数据源,与链接表无任何关系,因此数据流B中的产品表不会被刷新。假设此时数据流B中还有另一个来自数据流C的链接表,那么这个链接表由于来自数据流C,与数据流A无关,所以也是不会刷新的。
- 数据流A刷新,且数据流B中来自数据流A的链接表被禁用加载。首先刷新数据流A的所有表,然后检测到位于同一个工作区的数据流B引用了数据流A的产品总销量表,但该链接表禁用加载,因此不会自动触发数据流B的刷新,整个刷新流程结束。
- 数据流B刷新,且两个数据流的所有表都启用加载。首先刷新数据流B的所有表,其中包括来自数据流A的链接表。此时,数据流B中的产品表正常刷新,会从数据源里获取最新的数据。而数据流B中来自数据流A的链接表以及链接表的计算表也会正常刷新,但其只是与数据流A中的产品总销量表进行数据同步,而不是按照完整的引用链条的代码逻辑从头开始计算。然后需要注意数据流A处于引用的上游,不包含数据流B的任何表,因此不会触发链式刷新,所以最终数据流B中来自数据流A的链接表以及链接表的计算表的结果不变,因为数据流A的数据没变。简单来说就是数据流B中的链接表也会刷新,但其数据源为数据流A,而数据流A的数据没刷新,所以导致数据流B中的链接表的数据不变,此时从结果上来看就是刷了等于没刷。但当数据流B与数据流A分别位于不同的工作区时,就有可能出现数据流B中的链接表与数据流A的数据不一样的情况,此时数据流B的链接表会同步数据流A的数据,虽然也得到了更新,但这只是相对数据流A而言的,如果相对数据源而言,此时数据流A与数据流B中的链接表的数据可能都不是最新的。所以说,如果想彻底刷新某个包含链接表的数据流,除了需要刷新它自身,还要去刷新它引用的链接表所在的数据流。
下面再来看一个案例,该案例将更通俗易懂地解释这句话的含义:“链接表的刷新只是与其所在的源数据流进行数据同步,而不是按照完整的引用链条的代码逻辑从头开始计算”。
在本地PowerQuery里,有一个查询A,该查询从数据源上获取数据,如下图所示。
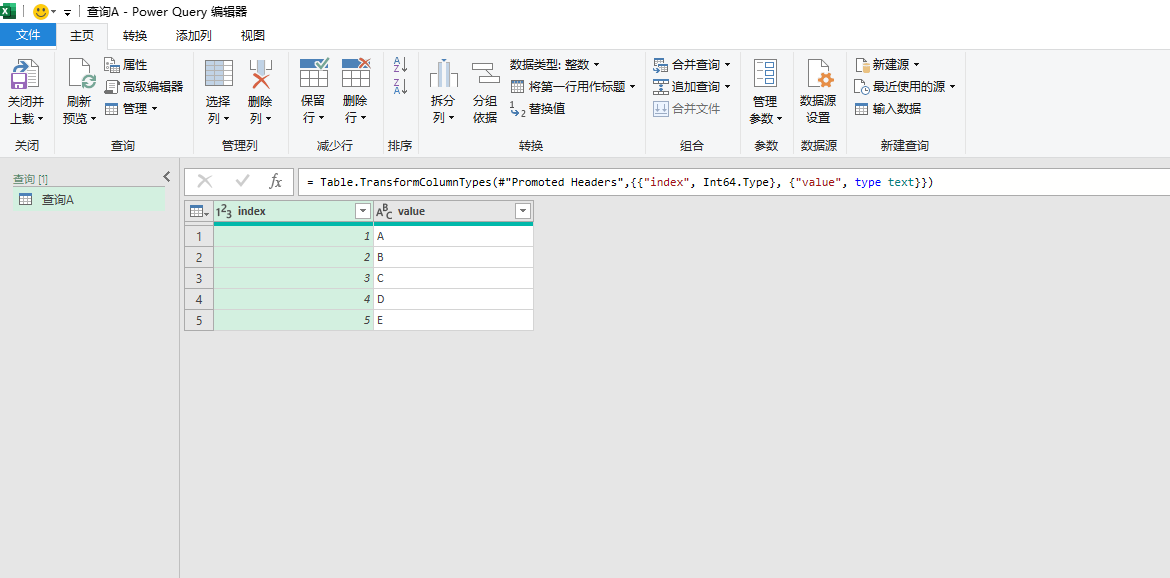
然后引用查询A,生成另一个查询,如下图所示。
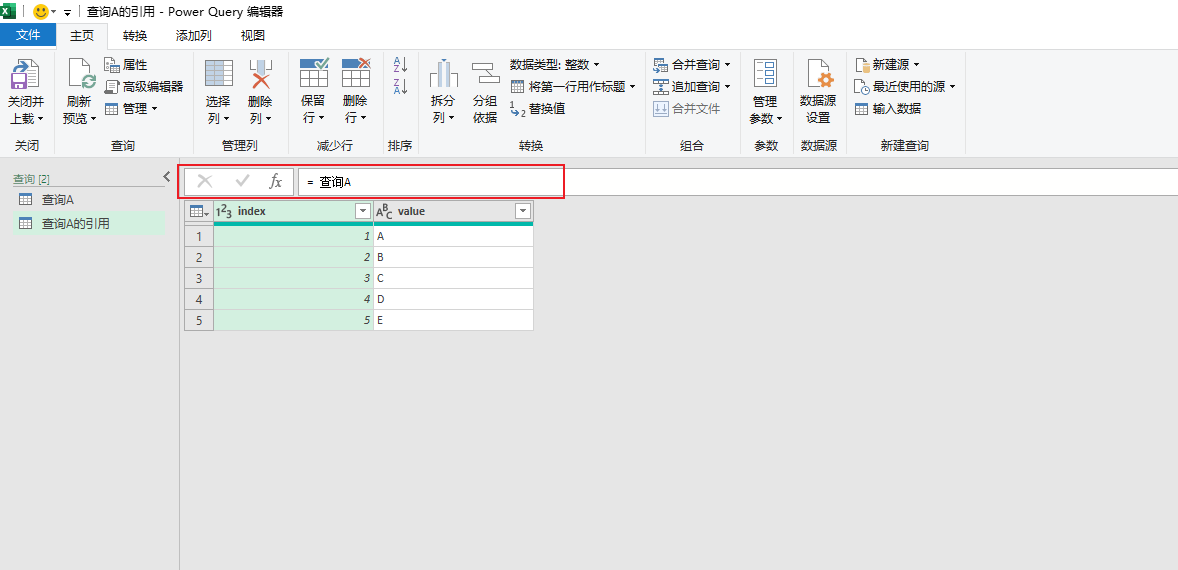
此时,在数据源里增加一行数据:index=6,value=F。然后刷新查询A的引用,结果如下图所示。
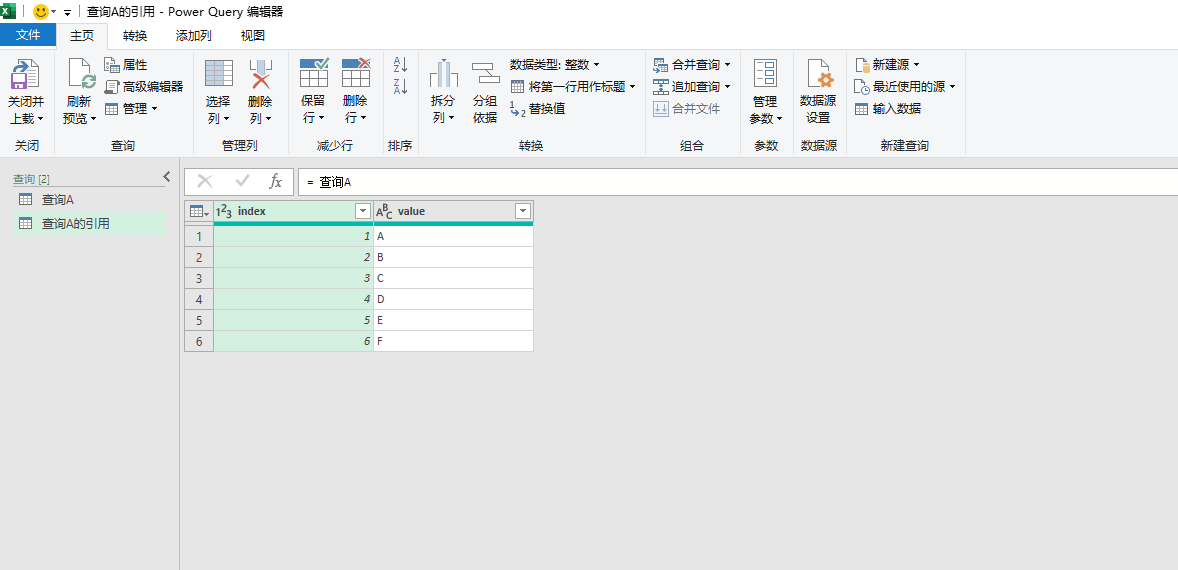
可以看到,查询A的引用被刷新后,其数据为数据源的最新数据。此时,查询A的数据如下图所示。
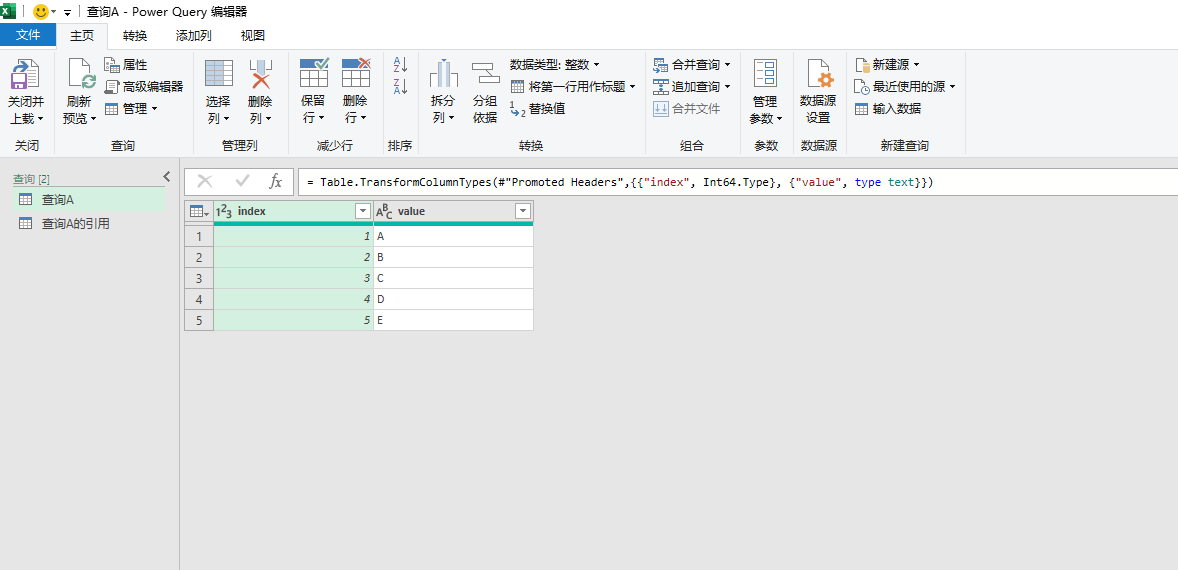
可以看到,作为引用世系的起点的查询A的数据竟然还是旧的数据。从这里可以看出,查询A的引用在刷新数据时,是按照完整的引用链条的代码逻辑从头开始计算的,因此刷新后的数据即为数据源的最新数据。假设查询A的引用在刷新后的数据与查询A一致,那么这种情况就是以查询A为数据源,可称为与引用源进行数据同步。
上面这个案例是使用本地PowerQuery进行演示的,引用的查询的刷新规则与数据流间的引用刚好是相反的,当然这不重要,这个案例主要目的是为了区分”与其所在的源数据流进行数据同步“,以及”按照完整的引用链条的代码逻辑从头开始计算“这两种行为。
总结
数据流其实就是一个云端化的PowerQuery再加上数据存储,与本地PowerQuery的使用基本一致,基本没有门槛,非常容易掌握。另外,虽然数据流可以在共享容量工作区中使用,但功能限制非常严重,因此最佳实践就是只在高级容量工作区中使用数据流,这样可以不用考虑各功能的限制,从而得到流畅的开发体验。