夕枫 | 笔绘人生
夕枫 | 笔绘人生最近DAX新出了个OFFSET函数,这个函数可以在指定的表中按给定的位置(行)进行偏移取值,与Excel中的OFFSET函数的作用有点类似。据说这个函数是PowerBI在为视图层操作所进行的布局,因此这个函数具有比较高的学习与应用价值,故本篇文章将分享我对该函数的一些理解与应用尝试,算是抛砖引玉吧。
由于官方文档暂时没有给出OFFSET函数的语法说明,也没有更详细的技术资料,所以本文的内容,包括语法结构等的说明,均为我在大量测试后所归纳总结出来的规律。就如盲人摸象一般,这些规律也许只能解释部分现象,并不一定完全正确,因此仅供参考!
OFFSET函数的语法结构
- 语法:
OFFSET(<OffsetNum>, <TableExpression> [,ORDERBY(<ColumnName> [,<Order> [,<ColumnName> [,<Order>]]...])])- 作用:
在按第三参数指定的排序方式排序后的第二参数的表中,从各个给定的起始位置(行)处,偏移指定的行数,返回偏移后的表。
- 参数:
| Name | Description |
|---|---|
| OffsetNum | 返回整数的表达式,用于指定偏移的行数,正数为向下偏移,负数为向上偏移,0则不偏移 |
| TableExpression | 返回表的表达式,在返回的表中,至少需要存在一个具有数据沿袭的列,并且具有数据沿袭的列都必须来自同一个表 |
| ORDERBY | 这是一个函数,用于指定如何对第二参数的表进行排序 |
| ColumnName | 排序依据列,来自第二参数的表中,并且该列必须具有数据沿袭 |
| Order | 用于指定排序依据列的排序方式,ASC、1、TRUE为升序,DESC、0、FALSE为降序,默认升序 |
上面给出了OFFSET函数的语法结构,看起来复杂,但其实很简单,可结合下面给出的一些用法示例来辅助理解:
OFFSET(1,ALL(ColumnName1,ColumnName2)) // 省略了ORDERBY结构,不推荐这种用法
OFFSET(1,ALL(ColumnName1,ColumnName2),ORDERBY(ColumnName1,ASC)) // 按ColumnName1升序排列第二参数返回的表
OFFSET(0,ALL(ColumnName1,ColumnName2),ORDERBY(ColumnName1)) // 省略了ColumnName1的排序方式,因此默认升序
OFFSET(-1,ALL(ColumnName1,ColumnName2),ORDERBY(ColumnName1,ASC,ColumnName2,ASC))
OFFSET(-1,ALL(ColumnName1,ColumnName2),ORDERBY(ColumnName1,ASC,ColumnName2))使用OFFSET函数时的一些注意事项
1、第二参数返回的表中,所有具有数据沿袭的列都必须来自同一个表。
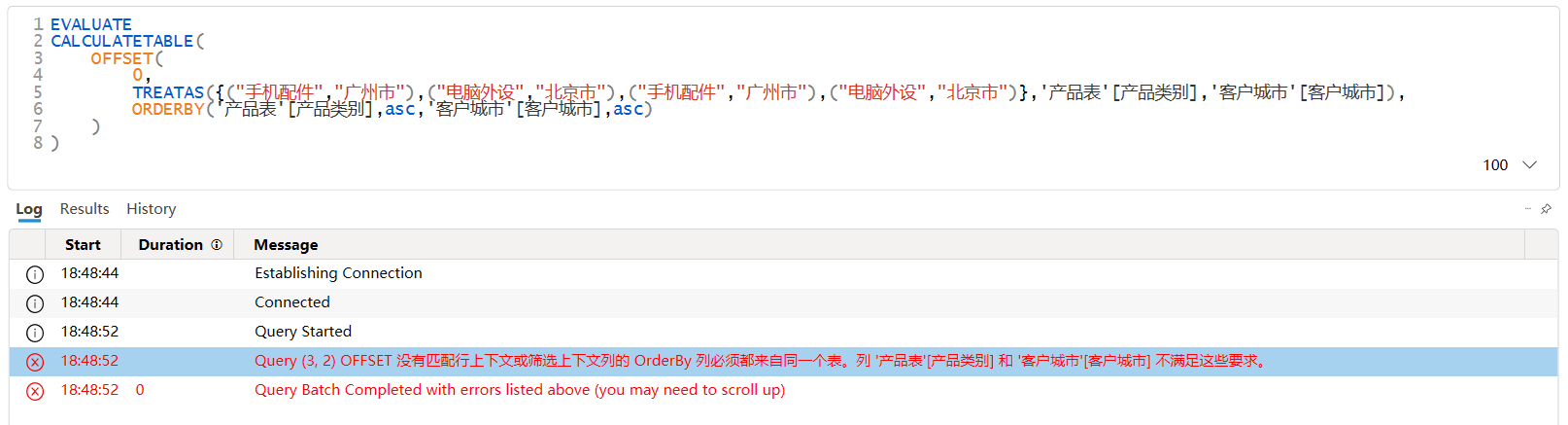
从上图可以看到,当第二参数的表中具有数据沿袭的列并不来自同一张表时,引擎将报错或出现异常。从第一个例子的错误提示中,错以为是ORDERBY函数中涉及到的列要来自同一个表,但第二个例子的ORDERBY函数仅使用了一个列,也同样出现了异常报错,因此问题并不是出现在ORDERBY函数。再加上另外的一些测试后,得出结论:第二参数返回的表中,所有具有数据沿袭的列都必须来自同一个表。
2、ORDERBY函数里引用的排序依据列必须来自第二参数的表,并且必须具有数据沿袭。
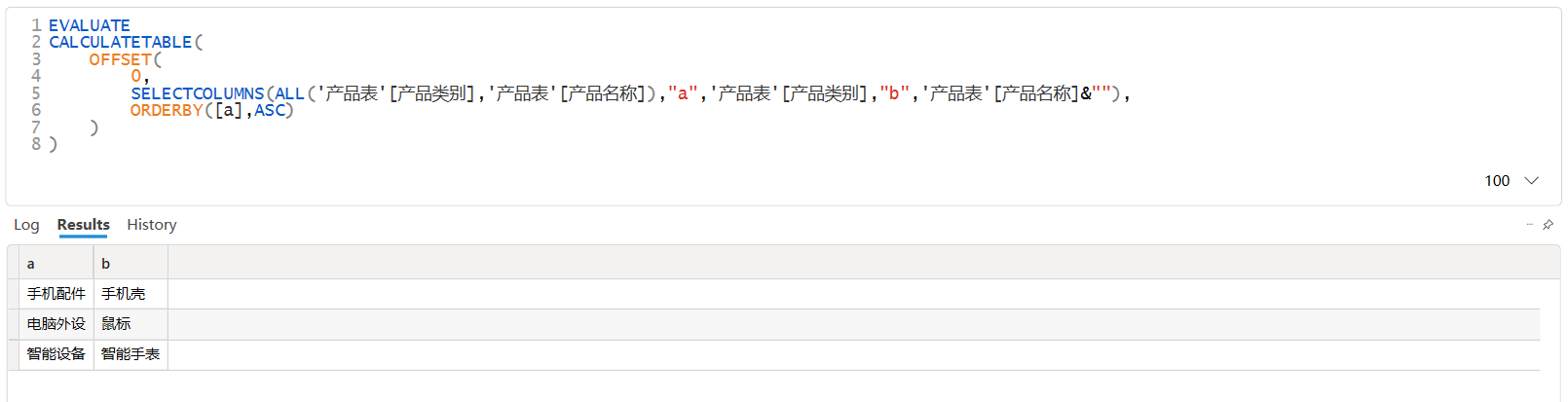


在上面这个案例中,OFFSET的第二参数使用了SELECTCOLUMNS函数,对产品名称列的数据沿袭进行了破坏,但保留了产品类别列的数据沿袭,然后在ORDERBY函数中分别使用产品类别(a)与产品名称(b)进行测试。从结果来看,具有数据沿袭的产品类别(a)可以正常返回结果,而数据沿袭被破坏了的产品名称(b)则出现了报错。根据错误提示可以得知:ORDERBY函数中的排序依据列不能是ADDCOLUMNS或SUMMARIZE等函数中添加的派生列,即ORDERBY函数中引用的列必须具有数据沿袭。
另外,从上面最后一个例子中可以看到,ORDERBY函数中引用了第二参数的表中不存在的列,然后出现了报错,所以ORDERBY函数里引用的排序依据列必须来自第二参数的表。
3、第二参数返回的表中,至少需要存在一个具有数据沿袭的列。
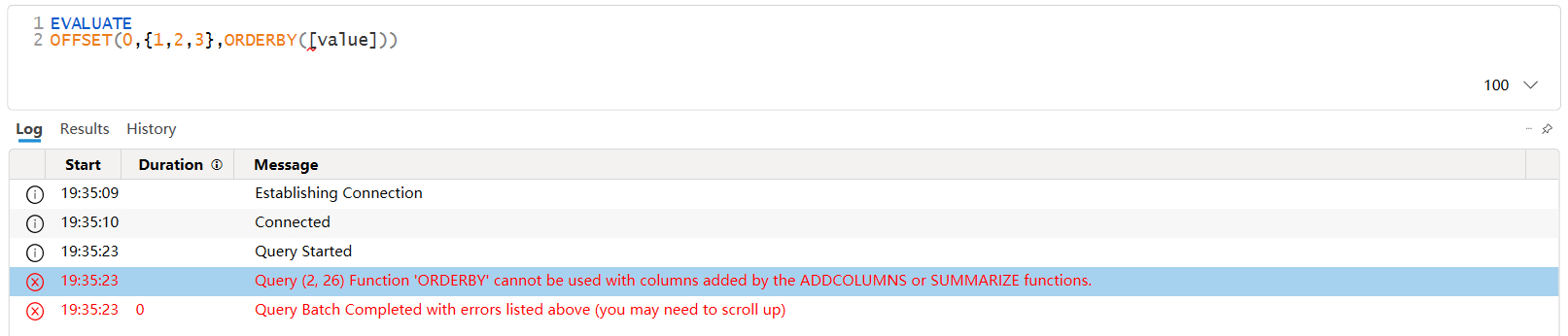
由于ORDERBY函数中引用的列必须具有数据沿袭,所以第二参数返回的表中至少需要存在一个具有数据沿袭的列,否则将会报错,如上图所示。
4、ORDERBY函数中,只有最后一个引用的排序依据列的排序方式可省略。
OFFSET(0,ALL(ColumnName1,ColumnName2),ORDERBY(ColumnName1))
OFFSET(-1,ALL(ColumnName1,ColumnName2),ORDERBY(ColumnName1,ASC,ColumnName2))5、ORDERBY函数这个整体可以省略,但非常不推荐,因为默认的底层排序规则并不明确,特别是第二参数具有多个列时。
6、PowerBI的代码智能提示暂时还不支持OFFSET函数,会出现红色波浪线的错误提示,但并不影响使用,忽略即可。
OFFSET函数的计值流程
经过各种测试,现将OFFSET函数的计值流程归纳总结为以下步骤描述:
- Step1. 在外部计值环境下计算第一参数与第二参数,得到偏移行数,以及未排序的偏移参照表。
- Step2. 将未排序的偏移参照表按ORDERBY函数指定的排序依据列与排序方式进行排序,得到排序后的偏移参照表。【下面的步骤中将排序后的偏移参照表简称为偏移参照表。】
- Step3. 找到ORDERBY函数中的各个排序依据列,以及排序依据列对应的基础表。【由于排序依据列必须来自偏移参照表并且要具有数据沿袭,而偏移参照表中具有数据沿袭的列必须要来自同一个表,因此各个排序依据列所对应的基础表都是同一个表。】
- Step4. 在外部计值环境下计算该表达式:
CALCULATETABLE(SUMMARIZE(基础表,排序依据列1,排序依据列2...)),将该表达式返回的结果称为定位列表。 - Step5. 在偏移参照表中,按排序依据列查找第一次出现在定位列表中的行,得到各个偏移起始位置。
- Step6. 在偏移参照表中,从各个偏移起始位置处,按Step1里计算得到的偏移行数进行偏移,返回偏移后对应的行形成的表
上面给出的是文字描述,可能不太好理解,因此下面结合案例来辅助说明。使用到的新建表表达式如下:
偏移规律示意 = OFFSET(1,ALL('产品表'[产品名称],'产品表'[产品类别]),ORDERBY('产品表'[产品类别]))结果如下图:

计值流程示意图如下:

下面再来看一个计算列下的案例,使用到的计算列表达式如下:
偏移规律示意-计算列 = OFFSET(3,SELECTCOLUMNS('产品表',"a",'产品表'[产品类别]),ORDERBY([a]))结果如下图:
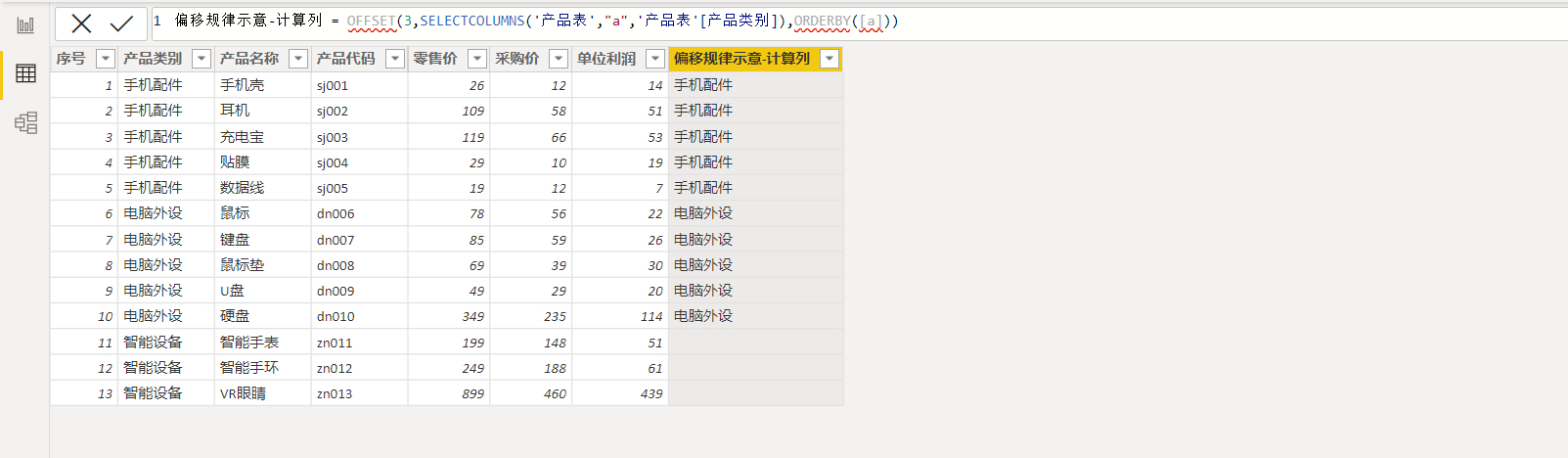
由于这是计算列,每一行所处的计值环境都不一致,因此下面只以产品类别为智能设备所对应的行来演示计值流程,探究结果为空的真相。计值流程示意图如下:

从上面的计值流程示意图中可以看到,智能设备对应的行中,计算列的所有值均为空其实是因为偏移参照表中的智能设备只有3个,而偏移行数却过大,因此才导致结果为空。而电脑外设与手机配件在偏移参照表中的项均大于3个,所以这两个项目对应的结果才不为空。
如果把偏移行数改为2,那么智能设备对应的行中,计算列的值应该也为智能设备,而不是空,因为偏移两行刚好能指向偏移参照表的最后一行。具体结果如下图所示:

相信经过上面这两个案例的演示,大家都能够掌握OFFSET函数的作用及运行规律,因此下面来看一下OFFSET函数的一些应用。当然这些应用都是尝试性的,并没有找到很好的套路,仅供参考。
OFFSET函数的应用
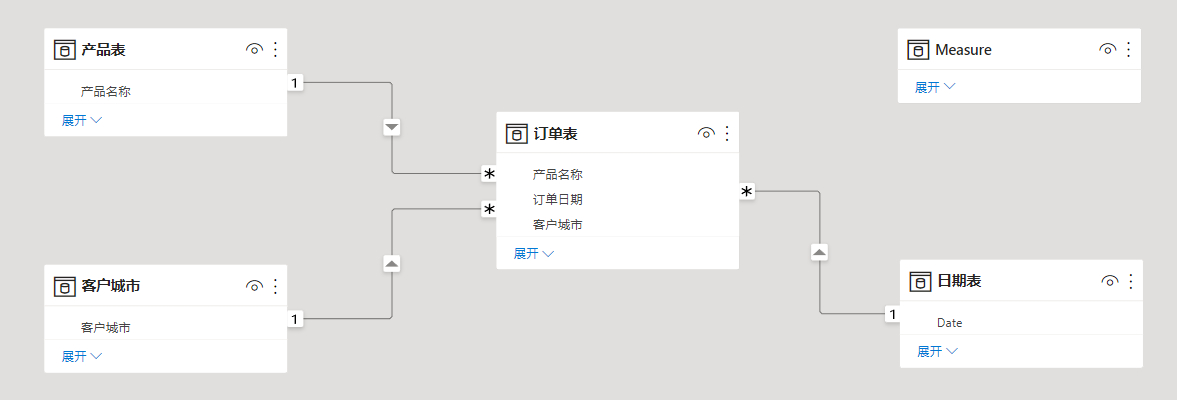
下面的案例均使用同一个数据模型,数据模型如下图:
然后新建一个基础度量值:
Sales = SUM('订单表'[销售额])下面的是各案例用到的度量值表达式,包括传统实现与OFFSET实现:
1、本周至今(WTD)
WTD =
CALCULATE(
[Sales],
DATESINPERIOD(
'日期表'[Date],
MAX('日期表'[Date]),
-WEEKDAY(MAX('日期表'[Date]),2),
DAY
)
)
WTD-offset =
CALCULATE(
[Sales],
TREATAS(
SELECTCOLUMNS(
GENERATESERIES(-WEEKDAY(MAX('日期表'[Date]),2)+1,0),
"a",OFFSET([value],ALL('日期表'[Date]),ORDERBY('日期表'[Date]))
),
'日期表'[Date]
)
)2、移动平均
MoveAvg = AVERAGEX(DATESINPERIOD('日期表'[Date],MAX('日期表'[Date]),-3,DAY),[Sales])
MoveAvg-offset =
VAR N = 3
RETURN
AVERAGEX(
SELECTCOLUMNS(
GENERATESERIES(-N+1,0),
"a",OFFSET([value],ALL('日期表'[Date]),ORDERBY('日期表'[Date]))
),
CALCULATE([Sales],TREATAS({[a]},'日期表'[Date]))
)3、获取最近的上一个有销售记录的日期
PreviousDay = IF([Sales]<>BLANK(),LASTDATE('订单表'[订单日期]<MAX('日期表'[Date])))
PreviousDay-offset = OFFSET(-1,ALL('订单表'[订单日期]),ORDERBY('订单表'[订单日期]))然后拉一个矩阵,将日期表的日期字段放在行字段,将上面三个案例的所有度量值放到值字段中,结果如下图所示:

需要注意,我把矩阵的总计栏给关闭了,因为上面的度量值并没有对总计栏处的计值环境做兼容,为了偷懒干脆关掉了。如果想复现上面的案例,别忘了关闭总计栏,或在每个度量值上添加屏蔽总计栏的代码。
OFFSET函数的Bug
在尝试更深入地使用OFFSET函数时,意外的发现了一个Bug。下面通过一个求最大连续数的案例来演示:
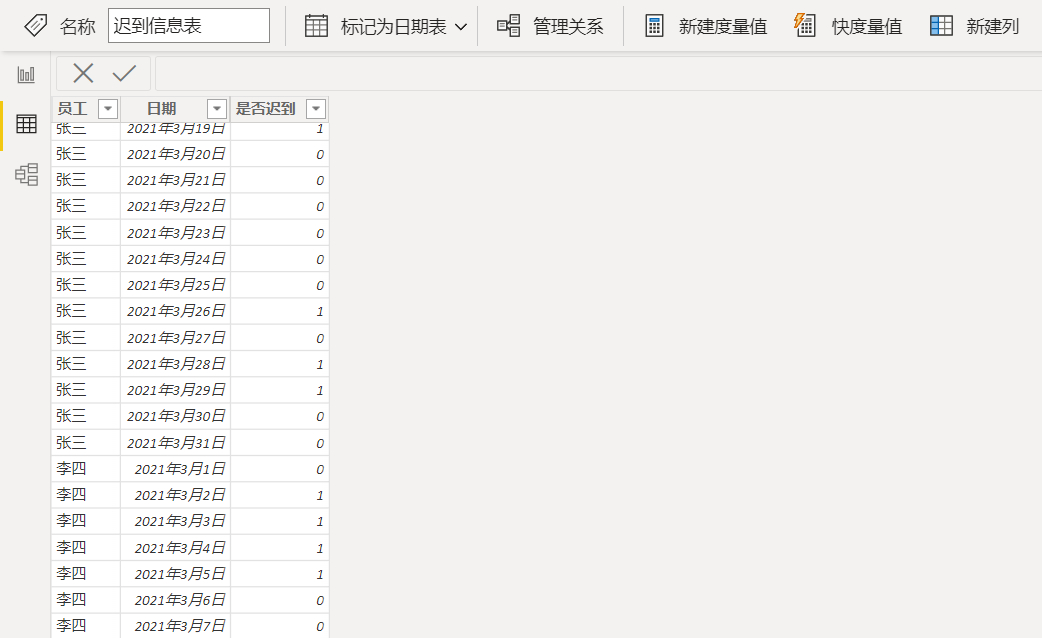
该案例仅使用到单个表,表结构与部分数据如下图:
使用到的度量值表达式如下:
最大连续迟到天数 =
MAXX(
SUMMARIZE(
ADDCOLUMNS(
'迟到信息表',
"grp",
SUMX(
FILTER('迟到信息表','迟到信息表'[日期]<=EARLIER('迟到信息表'[日期])),
MOD('迟到信息表'[是否迟到]+1,2)
)
),
[grp],
"num",IF([grp]=0,COUNTROWS('迟到信息表'),COUNTROWS('迟到信息表')-1)
),
[num]
)最大连续迟到天数-offset =
VAR vTb1 = ADDCOLUMNS('迟到信息表',"PreValue",MAXX(OFFSET(-1,'迟到信息表',ORDERBY('迟到信息表'[日期])),'迟到信息表'[是否迟到]))
VAR vTb2 = FILTER(vTb1,'迟到信息表'[是否迟到]+[PreValue]=1)
VAR vTb3 = ADDCOLUMNS(vTb2,"Start",IF('迟到信息表'[是否迟到]=1,'迟到信息表'[日期]),"End",IF([PreValue]=1,'迟到信息表'[日期]))
VAR vTb4 = ADDCOLUMNS(vTb3,"NewEnd",MAXX(OFFSET(1,vTb3,ORDERBY('迟到信息表'[日期])),[End]))
VAR vTb5 = FILTER(vTb4,[Start]<>BLANK())
VAR MaxDate = MAX('迟到信息表'[日期])
VAR vTb6 = SELECTCOLUMNS(vTb5,"Start",[Start],"End",IF([NewEnd]<>BLANK(),[NewEnd],MaxDate+1))
RETURN
MAXX(vTb6,[End]-[Start])*1最大连续迟到天数-offset2 =
VAR SearchTable =
TREATAS(
UNION(
{(MIN('迟到信息表'[日期])-1,0)},
SUMMARIZE('迟到信息表','迟到信息表'[日期],'迟到信息表'[是否迟到]),
{(MAX('迟到信息表'[日期])+1,0)}
),
'迟到信息表'[日期],
'迟到信息表'[是否迟到]
)
VAR StartList =
FILTER(
CALCULATETABLE(
OFFSET(-1,SearchTable,ORDERBY('迟到信息表'[日期])),
'迟到信息表'[是否迟到]=1
),
'迟到信息表'[是否迟到]=0
)
VAR EndList =
FILTER(
CALCULATETABLE(
OFFSET(-1,SearchTable,ORDERBY('迟到信息表'[日期])),
'迟到信息表'[是否迟到]=0
),
'迟到信息表'[是否迟到]=1
)
RETURN
MAXX(StartList,MINX(FILTER(EndList,'迟到信息表'[日期]>EARLIER('迟到信息表'[日期])),'迟到信息表'[日期])-'迟到信息表'[日期])*1将上面三个度量值放入以员工为行标签的矩阵中,结果如下图:

上图中,只有传统实现方法的结果才是正确的,而后面两个使用了OFFSET函数的度量值的结果都不正确。但将上面两个OFFSET实现的度量值放到查询中,手动模拟处于矩阵时的计值环境,结果却又正确了,如下图:


你以为这就完了吗,让我们回到报表的那个矩阵,刷新一下,再看下结果,如下图:


好家伙,这值竟然还不是固定的,每次刷新,第二个度量值处李四对应的值都会变化。所以,实锤了,这就是个Bug。
总结
首先再次声明,本文的所有内容都是基于大量测试后所归纳总结出来的规律,并不一定正确,也不一定能够解释所有现象,仅供参考!其次,OFFSET函数作为新出的函数,还有很多不完善的地方,遇到Bug也是在所难免的,期待其后续的改进。最后,OFFSET函数不能使用表达式的结果来作为排序依据,在这种情况下,它的应用场景更适合对本身就具有顺序属性的列进行偏移,比如日期列、索引列等。但OFFSET函数在日期列上的用武之地却并不是很大,因为已经有时间智能函数了。
总而言之,OFFSET函数可能是以后视图层操作的基础,非常具有学习与应用价值,值得花一点时间去掌握。另外,本文的内容可能具有一定的时效性,一切以官方文档为准!