夕枫 | 笔绘人生
夕枫 | 笔绘人生在Excel里,数据是以单元格的形式存储的,所以我们能够很方便的引用每一个值。但在DAX中,数据存储的最小单位是列,因此要想具体引用某个值就需要告诉DAX引擎:要引用的值位于哪个列的哪一行。其中,列由我们自己指定,而行则是由行上下文自动确定。
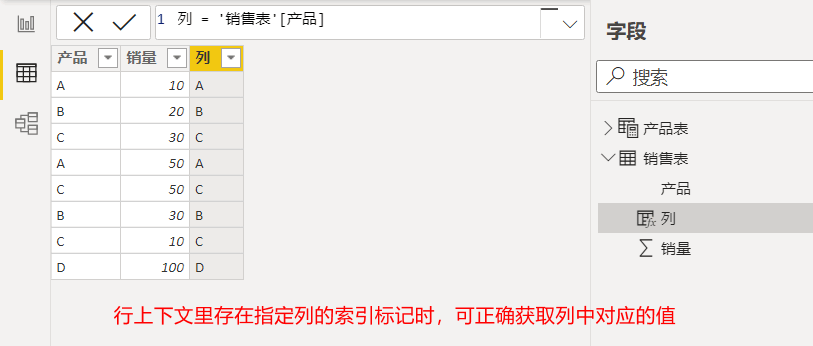
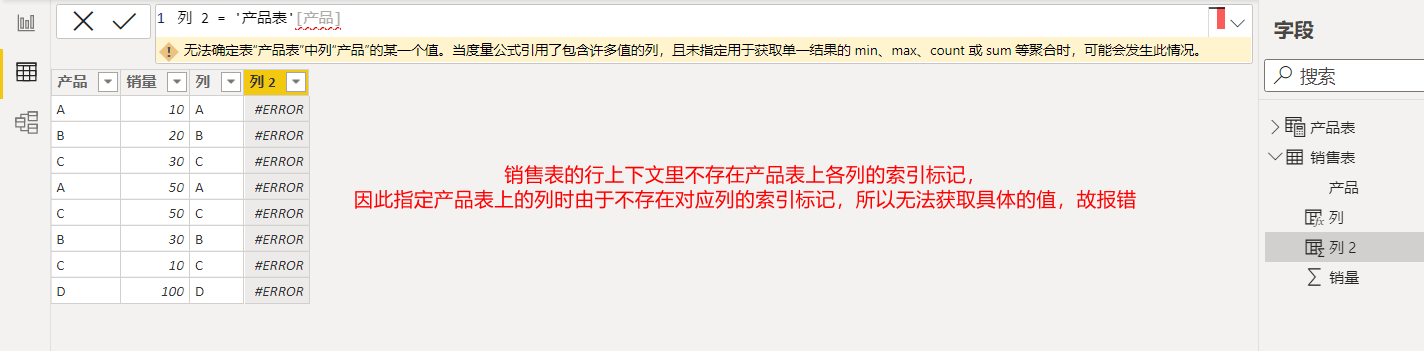
一个表可以由多个列组成,而DAX引擎会自动为每个列的每一行创建不同的索引标记,所有列在相同行上的索引标记则组成了表中每一行的行上下文。因此,当我们指定一个列后,DAX引擎会自动寻找该列在当前行上下文里的索引标记,然后根据索引标记去指定列中获取具体的值。若我们指定了一个列,但是当前行上下文里却不存在该列的索引标记,那么DAX引擎就无法确定要引用该列的哪一个值,因此这种情况下将会报错。具体如下图所示:
如果借用编程语言里的一些概念,那么行上下文就很好理解了。比方说,现在有一个数组,该数组存储了很多值,那么想要精确的获取数组中某个位置的值,那么是不是还需要一个数组索引才可以?那么这个数组可以类比为DAX引擎中存储的某个列,而该列每一行的索引标记可以类比为不同位置的数组索引。然后,对多个列而言,每个列都可以当作是一个数组,而每个列在每一行都有各自的数组索引,然后每个列在相同行的数组索引可以当作一个集合,这个集合就是某一行的行上下文。当然,这仅仅只是类比,在实际上还需要考虑性能等其它问题,因此在DAX引擎中肯定会有更优秀的处理方式,比如说把列压缩,然后通过字典来准确获取每一行的值等等,但原理是不变的。
为了更直观的描述,我做了一个示意图,该示意图说明了行上下文的创建过程以及根据行上下文获取对应值的逆过程,当然该示意图只是我个人给出,并不是DAX引擎内部的行为。具体如下图所示:

简单来说,行上下文就是一组索引标记的集合,在迭代到某一行时,DAX引擎就会根据这个索引标记的集合来获取各个列在当前行的数据,因此,我们可以把行上下文简单理解成正在计算的当前行的所有数据,这也是最方便的理解,但明确行上下文的真正指代对我们理解与掌握行上下文是很重要的。
此外,DAX引擎为基础表创建行上下文时,是以基础表的扩展表为对象创建的,即基础表的行上下文里不仅包含了基础表自身列的索引标记,还包括了扩展表上其它列的索引标记,但扩展表上不属于该基础表的其它列的索引标记不能直接引用。但在进行行上下文转换时,基础表的扩展表上的所有列都会转化成筛选器元组,每一列筛选的内容就是该列在当前行上下文里的索引标记所对应的实际值。简单来说就是:扩展表上不属于基础表自身列的其他列并不可见,也不能直接引用,当某个基础表被用作筛选器参数或者该基础表的行上下文被转换成筛选上下文后,其扩展表上不属于基础表自身列的其他列也会设置筛选器。
其实我们不需要关心DAX引擎内部对行上下文的转换与处理,因此,我们可以省略掉根据索引标记找到对应值的这个中间过程,直接把行上下文简单理解成正在计算的当前行的所有数据就好了。
DAX系列文章中涉及到的案例文件,均已上传到QQ群:344353627,若有需要,可自行加群获取。