夕枫 | 笔绘人生
夕枫 | 笔绘人生本篇文章将介绍固化筛选器与标准筛选器以及固化筛选器之间的交互行为,并简单介绍一下复杂筛选还原现象,最后对筛选上下文的修改方式做一点讨论。
固化筛选器需要筛选多个列,通常是由表转化而来。由于目前还没有介绍任何表函数,因此本篇文章就只介绍它们的交互行为,就不再举例演示。
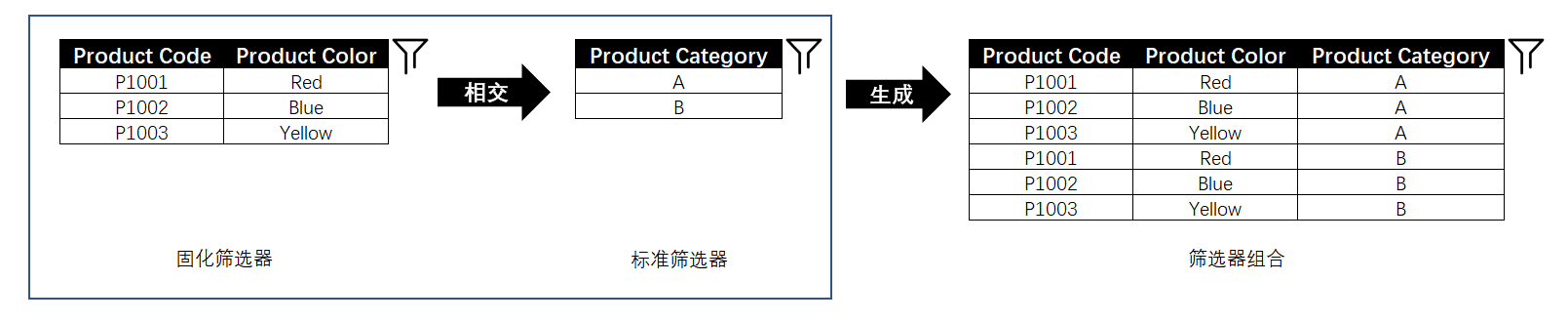
固化筛选器与标准筛选器的相交行为:
相交行为都很简单,也很好理解,把固化筛选器当成标准筛选器即可。具体如下图所示:
固化筛选器与固化筛选器的相交行为:
同样的,把两个固化筛选器都当作标准筛选器即可,如下图所示:

固化筛选器与标准筛选器的覆盖行为:
之前的文章中已经说过,相同列上的筛选器的交互方式是覆盖行为,就是用新增的筛选器覆盖旧的已有筛选器,这个覆盖行为可以理解成直接移除旧的已有筛选器。那么在涉及到固化筛选器的覆盖行为中,建议把覆盖行为都理解成直接移除旧的已有筛选器,这样会比较方便理解。具体如下图所示:

固化筛选器与固化筛选器的覆盖行为:
由于固化筛选器包含多个列,因此两个固化筛选器之间,有很大的可能是既存在相同列,也存在非相同列。那么这时,它们的覆盖行为就是只覆盖或者说只移除相同列,其他列则予以保留并且继续保持着这些列之前的原有关系,最后再与覆盖后的列相交。具体如下图所示:
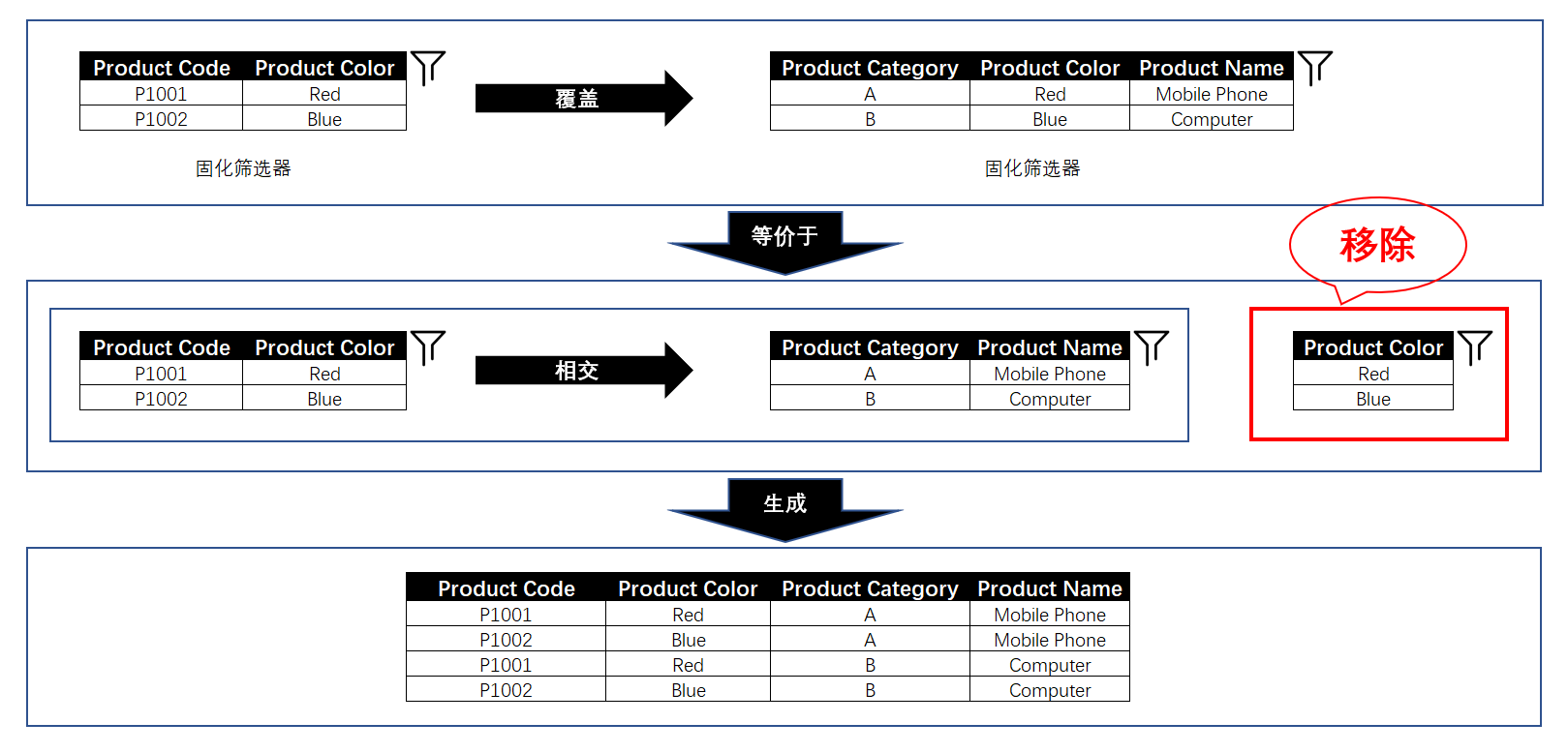
标准筛选器覆盖固化筛选器时的行为,与上图所示的固化筛选器覆盖固化筛选器的行为基本一致,就不再举例。
下面来看一下复杂筛选还原现象。所谓的复杂筛选还原,通常发生于固化筛选器的交互行为中,可以理解成这样:我们已经定义了一个很复杂的筛选器组合,希望度量值只在这个筛选器组合所筛选出的筛选上下文里计算,但由于疏忽了筛选器间的覆盖行为,导致这个很复杂的筛选器组合被破坏,使得结果不符合预期,那么这种情况就称为复杂筛选还原现象。
下面用一个例子来说明这种现象,由于要用到目前还没介绍的知识,因此我就简单介绍,大家就简单理解下,不懂的地方就交给未来的自己去理解吧。先来看一下使用到的度量值公式:
销售数量 = SUM('销售表'[销量])
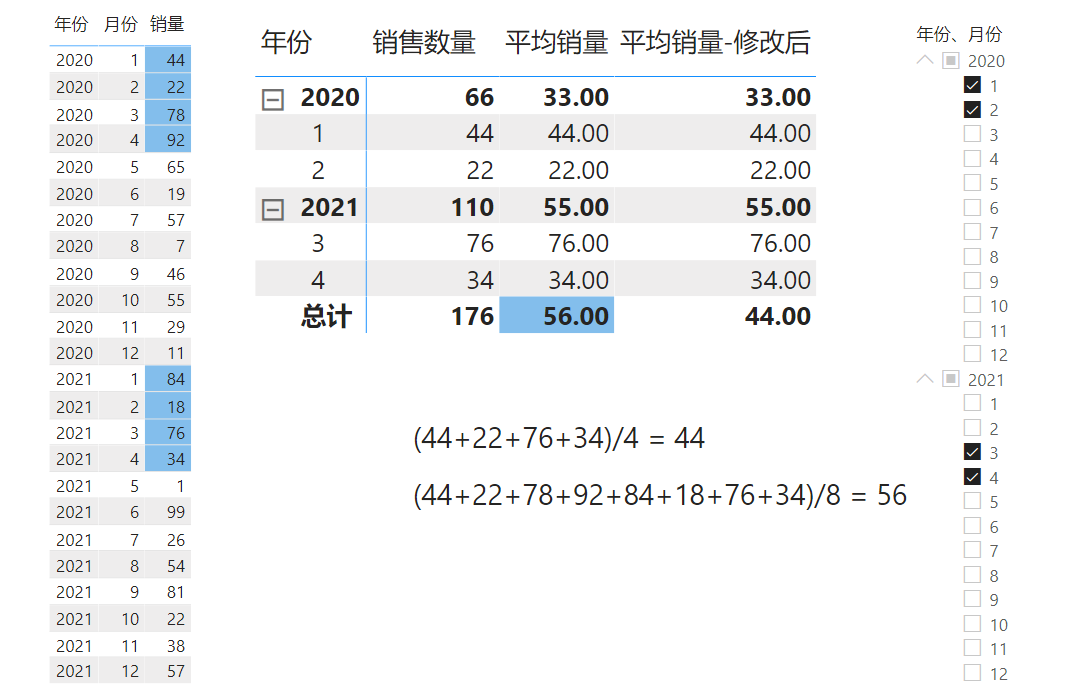
平均销量 = AVERAGEX(CROSSJOIN(VALUES('销售表'[年份]),VALUES('销售表'[月份])),[销售数量])这个例子只使用了单个表,数据与结果如下图所示:

在这个例子中,我们的目的是计算当前计值环境中所包含的各个月份的平均销量。在明细行里由于只有单个月,因此平均销量与当前月的销售数量相同。在小计行里,包含了所显示年份下属的两个月,因此小计行的值即为这两个月份的平均销量。而在总计行里,应该是包含了右边切片器选中的四个月份,那么平均销量的结果应该是44才对,但现在总计行的值却为56,这与我们预期的不符。
总计行结果不正确的原因就在于CROSSJOIN这个函数以及筛选器的覆盖行为。首先,CROSSJOIN函数是用来生成笛卡尔积组合的,而在总计行的筛选上下文里,有两个年份可见,有四个月份可见,那么就会生成一个具有八行的表,用伪代码可以表示成如下:
'销售表'[年份] = 2020 && '销售表'[月份] = 1 ||
'销售表'[年份] = 2020 && '销售表'[月份] = 2 ||
'销售表'[年份] = 2020 && '销售表'[月份] = 3 ||
'销售表'[年份] = 2020 && '销售表'[月份] = 4 ||
'销售表'[年份] = 2021 && '销售表'[月份] = 1 ||
'销售表'[年份] = 2021 && '销售表'[月份] = 2 ||
'销售表'[年份] = 2021 && '销售表'[月份] = 3 ||
'销售表'[年份] = 2021 && '销售表'[月份] = 4 然后,对于上面的每一行,由于发生了行上下文转换,使其转换成了一个一行两列的固化筛选器。而这个固化筛选器筛选的列,与切片器里筛选的两个列相同,使得切片器所选中的筛选器组合被覆盖掉了。导致最终的结果就是2020年与2021年的1到4月的平均销量,即上图左边标蓝的数据的平均值,而不是切片器中选中的四个月份的平均值。
我们需要警惕这种复杂筛选还原现象,但并不需要害怕,因为只要严格遵循各个函数的计值流程,并梳理清楚筛选器的交互行为,那么这是完全可控的。就好比上面这个例子,我们知道原因后,完全可以更改由行上下文转换而来的筛选器与已有筛选器间的交互方式,避免其发生覆盖行为,使其变成相交行为,从而使得总计栏的结果也符合预期。修改后的平均销量度量值的表达式如下:
销售数量 = SUM('销售表'[销量])
平均销量-修改后 = AVERAGEX(KEEPFILTERS(CROSSJOIN(VALUES('销售表'[年份]),VALUES('销售表'[月份]))),[销售数量])结果如下图所示:
上面这个例子中我只简单介绍了总计行的计值过程,对于明细行与小计行的计值过程你们感兴趣的可以自行去研究一下,我就只提醒一点,那就是初始筛选器间的交互方式都是相交行为,此外,上面切片器传递的是一个固化筛选器。那么复杂筛选还原现象就简单介绍到这里吧。
最后,我们来探讨一下修改筛选上下文的理解方式,这在之前的文章中也曾简单提及过。首先,我们来看一下筛选上下文的生成方式,如下:
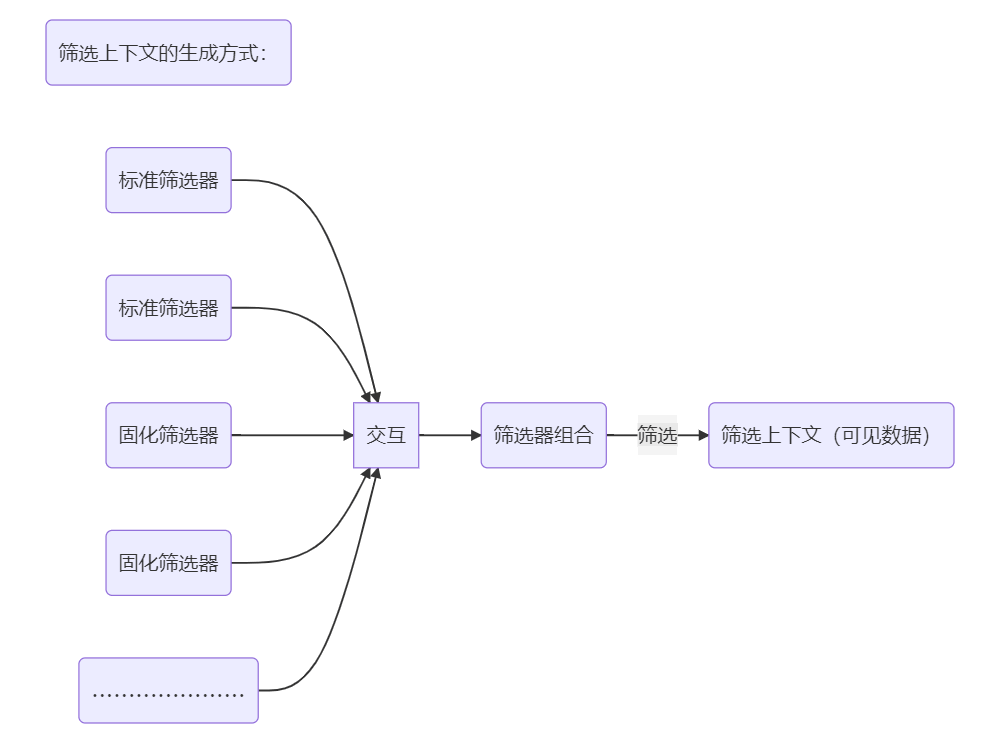
从上面的流程图中可以知道,筛选上下文的生成要经过两个步骤,那么我们要修改筛选上下文时也有两种选择,一种是修改现有的筛选器,另一种则是修改筛选器组合。这两种修改方式的本质其实都是一致的,都是通过更改筛选器的交互行为来修改筛选上下文,所以这两种修改方式其实都是一样的。
但是从理解的角度去看的话就并不一样了,如果是直接修改现有的筛选器,那么我们通常都是修改的标准筛选器,而修改筛选器组合,那么必定是修改的固化筛选器。由于标准筛选器更好理解与掌握,因此对于简单的问题一般都是理解成修改现有筛选器,而对于比较复杂的计值情况,如果仍理解成修改已有筛选器的话,那么就要重新执行生成筛选器组合的步骤,而这在复杂的计值环境下对大脑的运算能力有较高的要求,因此为了避免大脑内存不足,我建议在复杂计值环境下最好理解成修改筛选器组合。当然,你也可以两种理解方式混用,但这对大脑的内存、运算速度、以及经验等方面有较高的要求。因此,为了更好的掌控筛选上下文,我们需要对标准筛选器与固化筛选器的各种交互行为都有深刻地理解。
最后,筛选上下文的所有内容到这里就已经介绍完毕了,建议大家好好总结,构建好属于自己的思维模式。
DAX系列文章中涉及到的案例文件,均已上传到QQ群:344353627,若有需要,可自行加群获取。